

Understanding of Gremlin Graph Database

In the world of data management, graph databases have emerged as a powerful solution for handling complex, interconnected information. Unlike traditional relational databases, which structure data in tables and rows, graph databases use nodes, edges, and properties to represent and store data. This makes them ideal for analyzing relationships within large datasets. To work with graph databases, the graph provider supports one or more graph query languages, and one popular graph query language is Gremlin.
In this blog, we’ll explore what Gremlin is and how it fits into the ecosystem of graph databases. We’ll also look at the core concepts and syntax that make Gremlin unique, discuss the advantages of using it, provide practical examples, and offer a quick start guide to using Gremlin for graph analytics with the popular PuppyGraph database. By the end, you’ll have a comprehensive understanding of why Gremlin is a go-to choice for querying graph databases and how to harness its power in your own applications.
What is Gremlin?
Gremlin is a powerful query language and traversal framework designed specifically for interacting with graph databases. It’s part of Apache TinkerPop, an open-source framework that provides tools to work with graph data structures. As a "graph traversal language," Gremlin allows developers to think in terms of journeys across a network. For instance, if you wanted to find a friend of a friend in a social network, Gremlin enables you to express this traversal directly, hopping from one node to another across specified edges as the example shows below. This style of querying, called traversal, enables the analysis of relationships at any depth, making it possible to model real-world complexities like hierarchical organizations, recommendation systems, and network influence.

g.V().has('name', 'Alice').
out('friend').out('friend').values('name')Gremlin also provides APIs to graph analysis. Some common graph algorithms like page rank can be run easily also in traversal style if the graph supports GraphComputer.
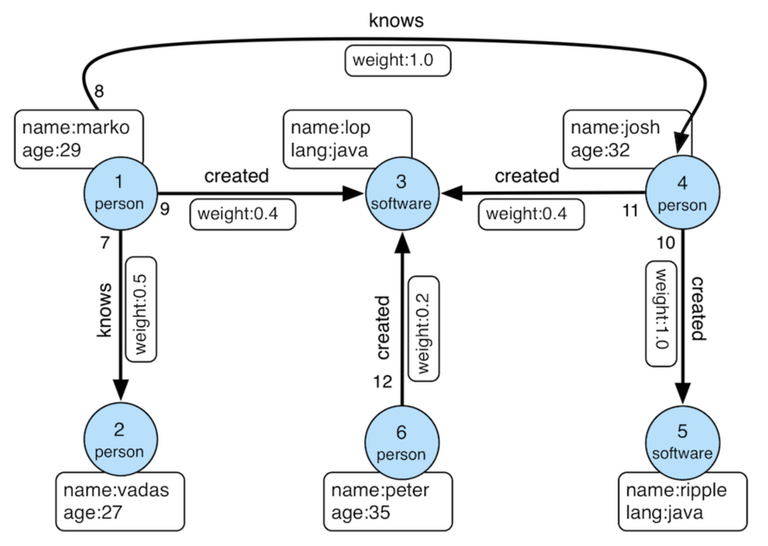
gremlin> g.withComputer().V().pageRank().
> with(PageRank.propertyName,'friendRank').
> valueMap()
==>[friendRank:[0.11375510357865541],name:[marko],age:[29]]
==>[friendRank:[0.14598540152719106],name:[vadas],age:[27]]
==>[friendRank:[0.3047200907912249],name:[lop],lang:[java]]
==>[friendRank:[0.14598540152719106],name:[josh],age:[32]]
==>[friendRank:[0.17579889899708231],name:[ripple],lang:[java]]
==>[friendRank:[0.11375510357865541],name:[peter],age:[35]]Gremlin isn’t limited to a single graph database platform—it’s a multi-purpose language that works with any graph database compliant with Apache TinkerPop. This portability makes Gremlin an excellent choice for companies that need flexibility and future-proofing in their data infrastructure. Its syntax can be embedded in popular programming languages like Java, Python, and Groovy, making it accessible to a wide range of developers.
In essence, Gremlin is both a language and a way of thinking about data. It shifts the focus from isolated data points to relationships and interactions, opening the door to new kinds of insights that are essential in today’s connected world. Whether you’re analyzing social interactions, financial networks, or cybersecurity threats, Gremlin offers a uniquely intuitive and powerful approach to exploring graph data.
What is a Gremlin graph database?
A graph database is an online database management system that uses a graph-based model to represent and store data. It supports Create, Read, Update, and Delete (CRUD) operations, allowing users to interact with data effortlessly. In graph databases, both nodes and edges are primary entities, forming the core elements of the data structure. Users interact with these databases through specialized query languages designed for graph data, such as Gremlin and Cypher. Although graph databases can vary in their technical implementation, their core purpose is consistent: presenting data as a graph structure to users. Some graph databases store nodes and edges as individual entities, while others might rely on relational or NoSQL databases as underlying technologies. These architectural choices impact aspects like performance, scalability, and cost. However, regardless of the internal structure, a graph database’s primary function is to display data as a graph, enabling users to intuitively explore and analyze relationships.
A Gremlin graph database is a database system tailored for storing, managing, and analyzing graph data structures and is compatible with the Gremlin query language. Gremlin offers flexibility and compatibility with various database platforms, owing to its integration with TinkerPop, an open-source framework. This compatibility allows Gremlin to operate across any TinkerPop-enabled databases, which support the Gremlin APIs. This cross-platform compatibility provides users with the freedom to switch or combine database providers without modifying the query language. Examples of TinkerPop-enabled databases include Amazon Neptune, Azure Cosmos DB, and PuppyGraph.
Key concepts and syntax in Gremlin
To effectively navigate and query graph databases with Gremlin, understanding a few key concepts is essential. These include traversal, traversal source, step, traverser, graph computer, and vertex program, all of which define how Gremlin approaches data within a graph.
- Traversal: Traversal is central to Gremlin's functionality. In simple terms, a traversal is a "path" through a graph, following connections between nodes (vertices) and relationships (edges) to uncover insights. Traversals can be customized to explore specific paths, patterns, or relationships, making it possible to express complex queries in just a few lines of Gremlin code. This concept allows users to efficiently explore paths, apply filters, or transform data across interconnected nodes.
- Traversal Source: The traversal source, often abbreviated as g, serves as the starting point for all traversals in Gremlin. It provides access to the graph’s vertices and edges, enabling users to begin a traversal by querying specific nodes or relationships. The traversal source is configured to connect to a specific graph instance and may vary depending on whether the traversal is executed on a single machine or a distributed system. In this way, g is like the entryway into the graph, initiating traversals that follow a defined path.
- Step: Steps are the building blocks of a Gremlin traversal. Each step performs a specific operation, such as filtering, mapping, or aggregating data. Steps can be chained together to create complex traversals, allowing for multi-step queries that explore relationships in depth. Common steps include out() for outbound connections, in() for inbound connections, has() to filter by property, and group() for aggregations. Steps define the actions taken at each stage of the traversal, giving users fine-grained control over the query.
- Traverser: The traverser is an entity that moves through the graph according to the rules specified in the traversal. As it moves from node to node, it carries information about the current position in the graph, enabling the traversal to apply filters, transformations, and other operations dynamically. Traversers are essential for tracking the progress and state of a traversal as it unfolds across nodes and edges.
- Graph Computer: For large graphs, Gremlin supports distributed processing through a component called the graph computer. It enables computations to be divided across multiple machines, allowing for efficient parallel processing of complex traversals. This feature is particularly valuable when dealing with extensive datasets, as it allows Gremlin to scale with data size, providing the resources needed to perform heavy-duty analysis on large graphs.
- Vertex Program: The vertex program is a specialized construct that allows Gremlin to perform complex, iterative computations across a graph. Often used with graph computers, vertex programs execute operations like pathfinding, centrality calculations, and other algorithms that require multiple passes over the data. Vertex programs are useful for advanced graph analytics where each node needs to participate in a computation that spans the entire graph.
These key concepts provide the foundation for creating powerful and flexible queries with Gremlin. By combining these elements, users can harness the full potential of Gremlin to reveal insights and uncover patterns within graph data. After understanding the core concepts, it's easy to grasp the syntax. It simply involves a traversal that starts with a source and is followed by a chain of steps (with step modulators).
In the "friend of friend" query example above, g is the traversal source, V is the start step selecting all vertices, and has is a filter step selecting only those vertices with the name "Alice." out is a step that specifies the outgoing edge to traverse, using the label 'friend.' Finally, values is a map step that retrieves the 'name' attribute of the vertices. The traverser keeps track of the current state throughout the traversal, including information like sack, side effects, and path history.
Even graph analysis syntax can be expressed through this graph traversal approach. In the example above, withComputer is a configuration step declaring the use of a graph computer, and pageRank is a step for the PageRank algorithm. The with step specifies that the property name for the PageRank results should be "friendrank," and finally, the valueMap step shows all the values after the algorithm has run."
Advantages of using Gremlin as a query language in graph databases
Gremlin offers a range of advantages that make it highly effective for querying and analyzing graph databases. One of its key strengths lies in its flexibility: as a traversal-based language, Gremlin enables users to easily navigate complex networks and uncover relationships that are challenging to model in traditional relational databases. With its focus on traversals, Gremlin makes it straightforward to follow paths, filter connections, and gain insights into deeply interconnected data, such as social networks or financial transactions.
Another advantage is Gremlin’s compatibility across various graph database platforms. As part of the Apache TinkerPop framework, Gremlin can be used with any TinkerPop-compliant database, including popular options like Neo4j, Amazon Neptune, and Azure Cosmos DB. This cross-platform compatibility enables organizations to avoid vendor lock-in and maintain flexibility in their database choices.
Gremlin’s support for parallel processing through graph computers also makes it efficient for large-scale graph analytics. It can scale across multiple machines, which is essential for handling massive graphs with billions of nodes and edges. Together, these capabilities make Gremlin an ideal choice for applications that rely on complex relationships, such as recommendation engines, fraud detection, and network security analytics.
Gremlin graph database examples
Several graph database vendors support the Gremlin query language, enabling users to perform complex traversals and analyses across various platforms. Here are some notable examples:
Amazon Neptune: A fully managed graph database service by Amazon Web Services (AWS), Neptune supports both the Property Graph model and the W3C's RDF standard. It allows users to query their data using Gremlin, SPARQL, and openCypher, providing flexibility in graph data management.
JanusGraph: An open-source, distributed graph database under The Linux Foundation, JanusGraph is designed for scalability and supports various storage backends like Apache Cassandra, HBase, and Google Cloud Bigtable. It integrates natively with the Apache TinkerPop stack, utilizing Gremlin for graph traversals.
OrientDB: An open-source NoSQL database management system written in Java, OrientDB is a multi-model database supporting graph, document, and object models. It manages relationships as in graph databases with direct connections between records and supports querying with Gremlin along with SQL extended for graph traversal.
Azure Cosmos DB: Microsoft's globally distributed, multi-model database service, Azure Cosmos DB offers a graph database service via the Gremlin API. This allows developers to build graph-based applications with the scalability and performance benefits of Azure's cloud infrastructure.
ArangoDB: A native multi-model database that combines graph, document, and key-value data models, ArangoDB supports graph queries through the Gremlin query language. This flexibility enables developers to work with different data models within a single database engine.
These examples demonstrate the widespread adoption of Gremlin across various graph database platforms, providing developers with powerful tools for managing and querying complex, interconnected data.
However, to use these graph databases, you typically need to import your data. This means performing ETL (Extract, Transform, Load). ETL processes typically involve extracting data from sources, transforming it to fit database requirements, and then loading it—a multi-step workflow that can significantly slow down data availability. "We will introduce a powerful graph database tool, PuppyGraph, in the next section. It does not require ETL and has high performance.
Getting started with Gremlin for graph analytics
Getting started with Gremlin is straightforward, especially for those familiar with graph databases. First, set up a TinkerPop-enabled graph database, such as Amazon Neptune, JanusGraph, or Azure Cosmos DB. Each of these platforms offers support for Gremlin queries, so you can begin exploring graph data with ease. You’ll need a Gremlin Console or a supported programming language like Java, Python, or Groovy, which allow you to interact directly with the graph. The Gremlin console of Apache TinkerPop is recommended for its simplicity and convenience for your initial attempt.
To initiate a query, you typically start with a traversal source, often represented as g, which serves as the entry point to the graph. From there, you can define traversals—paths through the graph data that follow nodes and edges to reveal patterns. For example, g.V() lists all vertices (nodes), while g.E() returns all edges. You can add specific steps like out() or in() to follow outbound or inbound connections, respectively.
New users can practice by performing simple queries, such as retrieving node properties or following basic paths, before moving on to more advanced traversals. With practice, Gremlin's syntax becomes intuitive, offering a powerful tool for uncovering relationships in complex graph data.
Using Gremlin with PuppyGraph
PuppyGraph is a graph analytics engine that allows users to query relational data in data lakes and data warehouses as a graph. The platform eliminates the need for ETL processes by transforming existing relational data stores into a unified graph model in under 10 minutes. PuppyGraph also uses min/max statistics, predicate pushdown, and vectorized data processing to further enhance efficiency and scalability.
With its support for both Gremlin and OpenCypher graph query languages, PuppyGraph caters to a wide range of users. It is available in a free community edition and a paid enterprise edition. The community edition can be deployed via Docker, while the enterprise edition is available via Docker and AWS AMI.
It's easy to start using Gremlin with PuppyGraph, as you can see in the short getting-started tutorials. To get started quickly, you can try Docker.
After starting the Docker container and waiting for the server to start, you can use PuppyGraph with a user-friendly web UI or from PuppyGraph's command line interface.

Once you're in the interface, if you have your own relational data, you can connect to it and upload a schema for your intended graph based on your data. You can then query your data with Gremlin and visualize your graph and query results with PuppyGraph's visualization tool. For experimentation, you can use the example data and schema.


There are multiple methods to query the graph with Gremlin. Besides those interactive tools, you can also try client drivers for various programming languages. If you are familiar with the Gremlin console of Apache TinkerPop, PuppyGraph also supports that.

Conclusion
In this article, we have explored the capabilities of Gremlin as a graph traversal language and its significance in the world of graph databases. Gremlin offers a unique approach to querying and analyzing data by focusing on relationships and connections, making it a powerful tool for understanding complex, interconnected datasets. Its compatibility with a variety of graph database platforms, including Amazon Neptune, Azure Cosmos DB, and JanusGraph, provides users with flexibility in choosing the best database for their needs.
PuppyGraph emerges as a game changer in this landscape. As the first graph query engine that allows users to query their relational data as a unified graph model within minutes, PuppyGraph eliminates the need for time-consuming ETL processes. Its support for Gremlin ensures users can leverage the power and flexibility of this versatile graph query language.
By combining the capabilities of Gremlin with the efficiency and accessibility of PuppyGraph, users can unlock new insights from their existing data, regardless of whether it is stored in a traditional relational database or a modern data lake. Whether you're exploring social networks, analyzing financial transactions, or investigating cybersecurity threats, Gremlin and PuppyGraph together offer a powerful toolkit for navigating the complex world of interconnected data.
PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


Interested in trying out PuppyGraph? Download the forever free Developer edition or book a free demo today with our graph experts.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install