
Understanding the Gremlin Graph API: A Comprehensive Guide
Data isn’t just about individual points—it’s about the connections that tie everything together. Understanding these relationships is where graph databases excel, and Gremlin is the tool that brings them to life.
Gremlin is a powerful, versatile, and standardized graph traversal language. It is part of the Apache Tinkerpop framework, and many graph providers support it. Gremlin is the query language that makes working with graph data intuitive and efficient. Part of the Apache TinkerPop framework, it's widely supported and lets you explore, analyze, and manipulate the connections within your graph data. While learning the basics of Gremlin is straightforward, unlocking its full potential requires a deeper understanding of its capabilities.
If you’re just starting with Gremlin and don’t want to dive straight into the official documentation, there are plenty of beginner-friendly resources to help, like tutorials or our previous blog post and PuppyGraph’s Gremlin docs.
In this post, we’ll take a closer look at the Gremlin API. We’ll break down its key concepts, show you how it works, and share practical examples along with best practices to help you get started or refine your skills.
What is the Gremlin API?
At its core, the Gremlin API is an interface defined by Apache TinkerPop, a graph computing framework designed to facilitate complex traversals over graph data structures. It provides a standard way to define, perform, and interact with graph traversals. While graph database providers have flexibility in implementing the Gremlin API in various ways, they must follow the standard definitions and structure of the API as outlined by TinkerPop. This consistency ensures that users can write Gremlin queries compatible with different platforms.
Apache TinkerPop itself includes an implementation called TinkerGraph, which serves as a simple demonstration environment for Gremlin’s capabilities. While some graph providers might add custom extensions to strengthen their offerings, this article focuses on the "standard" Gremlin APIs as defined in the official TinkerPop documentation. You can refer to the core Javadoc API document to see the details.
When we say "using Gremlin to traverse a graph," it’s important to note that users work primarily with a traversal rather than directly manipulating the graph. From the TinkerPop framework’s perspective, this distinction highlights two primary API types within Gremlin: the Structure API and the Process API.
TinkerPop Structure API
The Structure API defines how graph elements like vertices and edges are represented within the underlying graph structure, serving as a foundation for traversal processing. Although these APIs operate behind the scenes, they enable the traversal engine to carry out operations like navigating edges and nodes. Here are the key components of the Structure API:
- Graph: Maintains collections of vertices and edges, while also offering access to database functions such as transactions.
- Element: An abstract structure that represents both vertices and edges, each with a set of properties and a label.some text
- Vertex: Extends Element and includes both incoming and outgoing edges.
- Edge: Extends Element and connects vertices, also containing directional attributes.
- Property<V>: Represents a key-value pair for elements.some text
- VertexProperty<V>: A specialized property for vertices, supporting additional metadata properties.
In practice, these structure-level APIs are hidden from end users for traversal. Instead, they operate in the background as the engine processes each traversal step using these definitions. For instance, when a traversal step navigates from one edge to another, it leverages these structure APIs.
TinkerPop Process API
The Process API, meanwhile, is where Gremlin truly shines. It defines traversals and the systems for both OLTP (online transaction processing) and OLAP (online analytical processing) in graph analysis. Here are some essential components of the Process API:
- TraversalSource: Generates traversals specific to a graph, supporting domain-specific language (DSL) adaptations and execution engines.some text
- GraphTraversalSource: A GraphTraversalSource is the primary DSL of the Gremlin traversal machine. It provides access to all the configurations and steps for Turing complete graph computing. Any DSL can be constructed based on the methods of both GraphTraversalSource and GraphTraversal.
- Traversal<S, E>: Transforms objects of type S to type E in a functional data flow, enabling deep graph interactions.some text
- GraphTraversal: An expressive traversal language specifically tailored for raw graph elements (vertices, edges, etc.).
- Step<S, E>: A Step denotes a unit of computation within a Traversal. A step takes an incoming object and yields an outgoing object. Steps are chained together in a Traversal to yield a lazy function chain of computation.
- Traverser<T>: A Traverser represents the current state of an object flowing through a Traversal. A traverser maintains a reference to the current object, a traverser-local "sack", a traversal-global sideEffect, a bulk count, and a path history.
- GraphComputer: Executes graph analysis in parallel, often across a multi-machine cluster.some text
- VertexProgram: A code that runs across all vertices in parallel, communicating through message passing.
- MapReduce: Processes all graph vertices in parallel to yield a consolidated result.
Graph providers are responsible for implementing the Process API, allowing users to work with part of these components. Understanding these concepts is essential to understanding how Gremlin executes. This knowledge will help you write correct graph queries. If you're new to Gremlin, you might be curious since you haven't encountered these terms before. Don't worry, we'll explain them in the following sections with concrete examples.
How does gremlin api work?
Graph Traversal
As an end user, you typically access GraphTraversalSource and GraphTraversal directly when writing standard gremlin queries. Let’s consider a simple example with a demo “modern” graph of Tinkerpop.
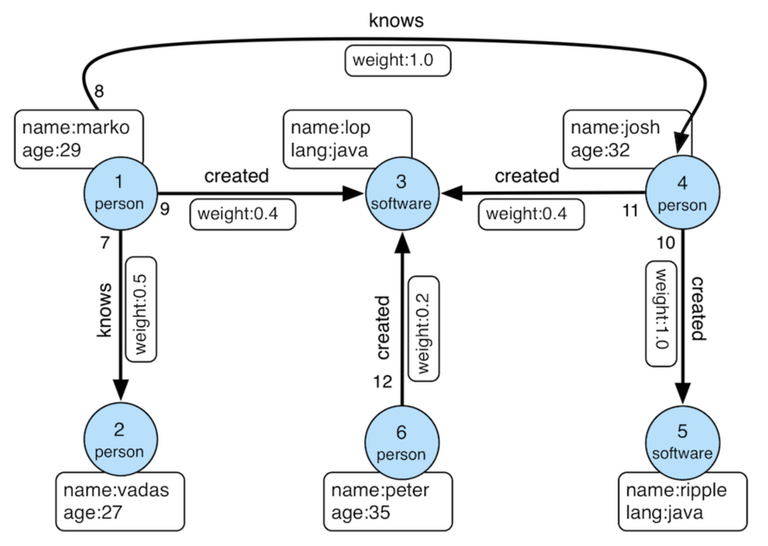
g.V().has('name','marko').out('knows').values('name')In this query, g represents the GraphTraversalSource, and the subsequent methods (V, has, out, values) form a chain of traversal steps provided by GraphTraversal. Each element in the chain serves a specific purpose: V is the starting step selecting all vertices, has step applies a filter, and so on.
In the Gremlin process engine, each of these steps is implemented by a class that conforms to the Step interface. For example, the has step is handled by the HasStep class within the org.apache.tinkerpop.gremlin.process.traversal.step.filter package. Note that these classes are part of Gremlin's underlying architecture rather than its core API, meaning they are not mandatory for graph providers. However, since GraphTraversal includes methods like hasValue, graph providers must support these operations to ensure compatibility within the Gremlin framework. For more detail, you may refer to the full API documentation.
When the has step is processed, the Gremlin engine interacts with the underlying data structure API to retrieve vertices that satisfy the filter condition. As the traversal progresses, a Traverser object keeps track of its current state, maintaining a record of traversal-local elements like “sack” (for individual element values) and traversal-global elements like “sideEffects” (which track shared information across traversers), while in the example, both “sack” and “sideEffects” are empty. Additionally, the traverser records the path history, such as [v1, e8, v4, ‘josh’] after the last step, representing the traversal’s progress and current location within the graph.
Graph analysis
For graph analysis, we typically use VertexProgram and MapReduce to run algorithms and sort out the analysis resutls. The GraphComputer executes a VertexProgram, which is essentially a piece of code run at each vertex in a logically parallel manner until a specific termination condition is met (e.g., reaching a set number of iterations or stabilizing when no further data changes occur in the graph).
When a VertexProgram is submitted, it’s duplicated across all workers in the graph. Although "worker" is not explicitly defined in the API, it is implicitly present in all GraphComputer implementations. In the simplest form, each vertex could be considered a worker; however, this approach is inefficient because it would require each vertex to maintain its own VertexProgram. In practice, workers partition the vertex set and manage the execution of the VertexProgram over the vertices within their assigned partitions.
These workers coordinate the VertexProgram.execute() method for their vertices in a bulk synchronous parallel (BSP) model. Vertices can communicate by exchanging messages in two ways: MessageScope.Local (to adjacent vertices) and MessageScope.Global (to any arbitrary vertex in the graph). After the VertexProgram completes, it may trigger any number of MapReduce jobs, either specified by the user through GraphComputer.mapReduce() or defined within the VertexProgram via VertexProgram.getMapReducers().
gremlin> graph = TinkerFactory.createModern()
gremlin> result = graph.compute().
program(PeerPressureVertexProgram.build().create()).
mapReduce(ClusterPopulationMapReduce.build().create()).
mapReduce(ClusterCountMapReduce.build().create()).
submit().get()
==>result[tinkergraph[vertices:6 edges:0],memory[size:2]]
gremlin> result.memory().clusterPopulation
==>1=5
==>6=1
gremlin> result.memory().clusterCount
==>2Here is an example of using Gremlin's GraphComputer to execute a VertexProgram with MapReduce jobs on a TinkerPop graph. The code begins by creating a sample graph with TinkerFactory.createModern(), generating a modern social network graph with six vertices and edges that represent relationships among them. Next, a computation is initiated on this graph by calling graph.compute(). A VertexProgram, specifically the PeerPressureVertexProgram, is then configured using .program(PeerPressureVertexProgram.build().create()). This program performs clustering by simulating a "peer pressure" effect, where each vertex aligns with a cluster based on its neighboring vertices, eventually forming clusters where vertices with similar neighbors group together.
After setting up the vertex program, two MapReduce jobs are added for further processing. The first job, defined by .mapReduce(ClusterPopulationMapReduce.build().create()), calculates the population within each cluster. The second, .mapReduce(ClusterCountMapReduce.build().create()), counts the total number of clusters.
When these configurations are complete, the computation is executed by calling .submit().get(), which submits the task to the GraphComputer and waits for it to finish. The result, stored in result, provides access to memory data generated during the computation. Accessing result.memory().clusterPopulation shows the distribution of vertices across clusters, with the output indicating that cluster 1 contains 5 vertices and cluster 6 has 1 vertex. Additionally, result.memory().clusterCount reveals the total number of clusters, which is 2 in this instance.
Working with data using Gremlin Graph API
Working with data using the Gremlin Graph API involves different approaches for embedding and managing graph data, each suited to specific operational needs and architectural choices. Three primary ways to interact with the Gremlin Graph API include using it in embedded mode, via the Gremlin Server, and through a graph provider.
In embedded mode, the Gremlin Graph API is integrated directly within the application's runtime environment. This approach is often used for local data processing or scenarios where the application and the graph database operate within the same memory space, allowing for efficient data access and manipulation without the overhead of network latency. Embedded mode is ideal for smaller or less complex graph workloads that don’t require large-scale distributed processing. For developers, this mode is straightforward since it enables them to directly instantiate the graph instance within the codebase. However, embedded mode requires memory resources proportional to the data size and can be limited by the host machine’s capabilities. Because of this, embedded mode is commonly used in prototyping, local testing, or when applications are self-contained.
The Gremlin Server offers a more versatile solution by allowing remote clients to interact with the graph through a server-based setup. The Gremlin Server runs as a separate process, exposing the Gremlin Graph API over the network and supporting multiple clients across various programming languages. This server-client architecture is beneficial for larger applications requiring distributed access to the graph database, as it allows multiple clients to execute Gremlin queries and leverage the server’s processing capabilities. Gremlin Server supports custom configurations, such as integrating with graph-specific caching and transaction handling, making it suitable for production-grade deployments. Since it centralizes graph access, the Gremlin Server can effectively handle concurrent client requests, providing isolation and scalability that are hard to achieve in embedded mode. However, network latency can be a factor, especially with extensive or complex graph queries.
Lastly, working with Gremlin through a graph provider enables integration with cloud or specialized database providers that offer managed graph database solutions. This approach is particularly beneficial for applications with heavy graph workloads, requiring scalability and availability beyond the capabilities of a single server instance. Graph providers often support high-performance storage backends and distributed architectures, making them suitable for large-scale, real-time applications, such as recommendation engines and social networks. These providers manage data storage, replication, and sharding, allowing applications to focus on query logic without worrying about infrastructure maintenance. Examples include services like Azure Cosmos DB, Amazon Neptune and PuppyGraph, which offer managed environments for graph data and native Gremlin API support. The flexibility of using graph providers lies in their ability to handle massive datasets while providing robust security, fault tolerance, and compliance features, which are essential for enterprise applications.
Gremlin Graph API examples
In this section, we will see some additional Gremlin query examples to illustrate more features.
Here are several Gremlin query examples to illustrate the specified concepts:
Basic vertex and edge addition and deletion
This example demonstrates how to create vertices and edges in a graph using the addV() and addE() steps.
g.addV('person').property('name', 'Alice').property('age', 30).
addV('person').property('name', 'Bob').property('age', 25).
addE('knows').from(V().has('person', 'name', 'Alice')).to(V().has('person', 'name', 'Bob'))This query adds two vertices with the label 'person' and then adds an edge labeled 'knows' between them.
g.V().has('person', 'name', 'Alice').drop()This query deletes the vertice of ‘Alice’. Note deleting a vertex will automatically delete all edges connected to that vertex.
Using configuration steps
Many methods on the GraphTraversalSource are designed to configure the source before use. This configuration affects how traversals are created. You can identify configuration methods by their names, which typically use "with" as a prefix.
g.with('providerDefinedVariable', 0.33).V()In this example, each new traversal created this way will have the "providerDefinedVariable" set to 0.33. It can be further processed and configured by the process engine.
For OLAP processing, you can use withComputer() like this:
g.V().withComputer().both().hasLabel('person').
values('age').groupCount().next()This runs the traversal on a graph computer for large-scale analytics.
Side effects and sack example
The sideEffect() step allows you to store intermediate data without affecting the traversal itself, while sack helps carry values along a traversal.
gremlin> g.V().sideEffect(outE().count().aggregate(local,"o")).
> sideEffect(inE().count().aggregate(local,"i")).
> cap("o","i")
==>[i:[1,1,1,0,0,3],o:[0,0,0,3,2,1]]
gremlin> g.withSack(1.0f).V().
> repeat(outE().sack(mult).by('weight').inV()).times(2).
> sack()
==>0.4
==>1.0The first query computes the out-degree and in-degree for each vertex. The second query computes the multiplication of ‘weight’ along the traversal.
VertexProgram example
VertexPrograms are often run with a graph computer in a way similar to traversal as a step.
PageRank example
PageRank measures the importance of each vertex based on the number and quality of incoming links.
gremlin> g.withComputer().V().pageRank().
> with(PageRank.propertyName,'friendRank').
> valueMap()
==>[friendRank:[0.11375510357865541],name:[marko],age:[29]]
==>[friendRank:[0.14598540152719106],name:[vadas],age:[27]]
==>[friendRank:[0.3047200907912249],name:[lop],lang:[java]]
==>[friendRank:[0.14598540152719106],name:[josh],age:[32]]
==>[friendRank:[0.17579889899708231],name:[ripple],lang:[java]]
==>[friendRank:[0.11375510357865541],name:[peter],age:[35]]This assigns a PageRank value to each vertex in the graph based on incoming edges.
Peer pressure example
Peer Pressure is a community-detection algorithm. It labels vertices based on their neighbors’ majority label.
gremlin> g.V().peerPressure().
> with(PeerPressure.propertyName, 'cluster').valueMap()
==>[cluster:[1],name:[marko],age:[29]]
==>[cluster:[1],name:[vadas],age:[27]]
==>[cluster:[1],name:[lop],lang:[java]]
==>[cluster:[1],name:[josh],age:[32]]
==>[cluster:[1],name:[ripple],lang:[java]]
==>[cluster:[6],name:[peter],age:[35]]After running this, each vertex is assigned a 'community' label indicating which community it belongs to, based on its neighbors' influence.
Note that the pageRank step and peerPressure step are VertexComputing steps and as such, can only be used against a graph that supports GraphComputer (OLAP).
Best practices for using the Gremlin Graph API
When working with the Gremlin Graph API, following best practices can help you optimize performance, maintain portability, and make informed choices tailored to your application’s requirements.
Avoiding the Graph API for enhanced portability
While the Graph API offers direct access to core graph elements such as vertices and edges, it is generally recommended to avoid relying heavily on it for building applications intended for diverse graph systems. Using the Graph API can introduce dependencies specific to a particular graph implementation, limiting the portability of your code. Instead, Gremlin traversals provide an abstraction layer, offering a consistent interface across TinkerPop-enabled systems. By focusing on Gremlin traversals, you can develop more adaptable applications that maintain functionality regardless of the underlying graph database engine.
Use indexing strategically
Indexes can dramatically improve the speed and efficiency of traversals by reducing the volume of data processed in each query. For properties that are frequently accessed, such as unique identifiers or commonly queried attributes, consider creating indexes to boost performance, especially in large graphs. However, indexing comes with trade-offs: it increases storage requirements and may impact write speeds. Using indexes judiciously is key to maintaining a balance between traversal speed and system overhead.
Leverage Gremlin steps efficiently
One of Gremlin’s strengths lies in its comprehensive set of built-in traversal steps, which can streamline data manipulation and reduce the need for client-side processing. Use steps like filter, map, and choose to apply transformations and conditions directly within the graph query, minimizing data transfer and increasing efficiency. For filtering, the has, is, and where steps allow you to narrow down results close to the source, eliminating the need for unnecessary traversals. Additionally, the dedup() step helps avoid redundancy by removing duplicate paths, which can be essential for optimizing performance in traversals that involve high redundancy.
Understanding the differences between OLTP and OLAP
Gremlin Graph API applications can be optimized by understanding the distinction between OLTP (Online Transactional Processing) and OLAP (Online Analytical Processing) graph systems. OLTP systems are designed for real-time, transactional workloads that involve random access patterns. These systems are ideal for applications requiring frequent, small-scale updates and low-latency responses. In contrast, OLAP systems are optimized for large-scale data analysis, capable of handling extensive datasets through parallel processing. Determining whether your application requires the real-time capabilities of OLTP or the analytical power of OLAP is essential for selecting the right approach.
Choosing the appropriate language variant
The Gremlin ecosystem includes several language variants—such as Gremlin-Groovy, Gremlin-Java, Gremlin-Python, Gremlin-JavaScript, and Gremlin-Go—each suited to different development environments and developer expertise. When selecting a language variant, consider factors like developer familiarity, the operational environment, and the capabilities of the graph system. For instance, Gremlin-Python and Gremlin-JavaScript are commonly chosen for web-based applications, while Gremlin-Java is often preferred in server-side environments with robust integration requirements. Selecting the language variant that aligns with your application’s environment and development team’s skills can streamline development and improve system integration.
Conclusion
Getting started with Gremlin is simple, but mastering it requires a deeper dive into the Gremlin API. By understanding key components like TraversalSource, Traversal, Step, and Traverser, you can unlock the full potential of graph traversal.
This post covered practical use cases and shared best practices to help you navigate the Gremlin API with confidence. For those ready to take their skills further, exploring the official documentation, Javadocs, and source code is the next step toward becoming a Gremlin expert. If you're interested in running Gremlin queries directly on your relational data, PuppyGraph offers a zero-ETL solution with petabyte-level scalability.
PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


Want to try it out for yourself? Download PuppyGraph’s forever-free Developer Edition, or book a demo with our graph team to walk through your use case.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.


