
Gremlin: Query Your Graph By Traversal
Gremlin is a graph traversal language, perfect for exploring complex connections. As part of Apache TinkerPop framework, it powers applications like social networks and fraud detection. This article will help you understand what Gremlin is, its basic syntax, and other key features, with a particular focus on its role as a graph query language from the user perspective.
What is Gremlin?
Gremlin is the graph traversal language for Apache TinkerPop, designed as a functional, data-flow language that allows users to efficiently express complex traversals or queries on a property graph. A traversal refers to the process of navigating through the elements of a graph (vertices, edges, properties) to retrieve data, update the graph, or compute aggregations.
Before exploring traversal and core concepts further, let's first provide a broader overview of the Apache TinkerPop framework to give you the big picture.
Apache TinkerPop is an open-source graph computing framework that provides a common interface and set of tools for processing and traversing graph data. As a framework, TinkerPop offers several key advantages:
- It provides a predefined structure with well-defined components for working with graphs, allowing developers to focus on problem-solving rather than building basic graph functionality.
- TinkerPop's common interface abstracts the complexities of different graph databases, enabling developers to write code that works across multiple systems without worrying about underlying implementations.
- The framework includes reusable components like the Gremlin traversal language and Gremlin Server, providing ready-made solutions for common graph operations.
- TinkerPop is designed for integration and extensibility, working with various graph storage systems and distributed computing platforms, and supporting plugins for customization.
- It offers developer guidelines and best practices, helping teams maintain consistency and avoid pitfalls when building graph-based applications.
These features make TinkerPop a powerful tool for developers working on graph-based projects of any scale. If your graph system is TinkerPop-enabled, you can communicate with it as a user by writing Gremlin queries.
Core concepts of Gremlin
To appreciate Gremlin's power, it's essential to grasp its core concepts centered around graphs and, most importantly, traversal.
Graph structure
Graph structure in Gremlin forms the foundation of how data is organized and queried. A graph consists of vertices (also known as nodes) and edges. Vertices represent entities in the graph, while edges represent relationships between these entities. Both vertices and edges can have properties, which are key-value pairs that provide additional information about the element. This structure allows for flexible and intuitive representation of complex data relationships. TinkerPop 3.x introduced support for multi-property and meta-property on vertex properties in Gremlin. These features further enhance Gremlin's expressiveness.
Graph traversal source
The Graph Traversal Source, commonly represented as 'g', is the starting point for all graph traversals in Gremlin. It serves as a factory for creating graph traversals and encapsulates the configuration and strategies used for querying the graph. By providing a consistent entry point, the Graph Traversal Source allows users to initiate traversals like g.V() or g.E() to begin exploring vertices or edges respectively. It abstracts away the underlying graph implementation, ensuring that Gremlin queries remain consistent regardless of the specific graph database being used.
Traversal
Traversal is a core concept in Gremlin, referring to the process of navigating through the graph. It's often described as "walking" through the graph structure. Traversals begin at specific points in the graph and move to other connected elements. They can vary from simple operations, such as identifying all neighbors of a vertex, to more complex queries involving multiple steps and conditions. Think of traversal as a sequence of steps, which we will explore in detail later.
Step
Steps are the core building blocks of traversals in Gremlin. While there's a rich variety of steps available in Gremlin's library, they are fundamentally based on five key types of operations:
- Map steps transform the incoming traverser's object into another object. The transformation is one-to-one. This allows for direct conversion or modification of data as it moves through the traversal. A few example steps are: value(), label(), select(), match().
- FlatMap steps are similar to map steps, but they transform the incoming object into an iterator of other objects. The transformation is one-to-many. This is useful when a single input needs to produce multiple outputs. A few example steps are: out(), inE(), bothV(), unfold().
- Filter steps determine whether a traverser is allowed to proceed to the next step or not. They act as a gatekeeper, controlling the flow of data based on specified conditions. A few example steps are: has(), dedup(), where(), is().
- SideEffect steps allow the traverser to proceed unchanged, but perform some computational side effects in the process. This is useful for operations like logging or aggregating data without altering the main traversal. A few example steps are: group(), groupcount(), aggregate(), sideEffect().
- Branch steps split the traverser and send each part to different locations in the traversal. This allows for complex, condition-based routing of data through different paths of the query. A few example steps are: choose(), local(), repeat(), union().
Nearly every step in Gremlin's GraphTraversal interface extends one of these five fundamental step types: MapStep, FlatMapStep, FilterStep, SideEffectStep, or BranchStep. By combining these different types of steps, users can create powerful and flexible traversals.
Step modulators
In a traversal query, not all chained elements are actual steps. Some are step modifiers that alter the behavior of the preceding step. Examples include by() and as(). The by() step modifier is used to specify how elements should be processed or ordered in the preceding step. It's particularly useful with steps like group(), order(), and project(). The as() step modifier is used to label steps in a traversal, allowing you to reference them later in your query. You can use the label later in the traversal with steps like select(), where(), or match().
Anonymous traversals
Anonymous traversals are those that do not start with a V or E step. These are created using the double underscore (__) syntax, though the __ can often be omitted.
gremlin> g.V().project('vertex', 'degree').by(id()).by(both().count())
==>[vertex:1,degree:3]
==>[vertex:2,degree:1]
==>[vertex:3,degree:3]
==>[vertex:4,degree:3]
==>[vertex:5,degree:1]
==>[vertex:6,degree:1]This query prints the ID and degree (number of adjacent edges) of each vertex. It uses by() step modifiers with embedded anonymous traversals to achieve this.
Traversers
Traversers are objects that move through the graph during a traversal. Each traverser represents a current position in the graph and carries its own state. During a traversal, traversers can be dynamically created, filtered, or transformed as needed. While navigating, each traverser maintains a record of its location, path history, and any relevant data. By manipulating these traversers, Gremlin can perform sophisticated graph analyses, pattern matching, and data retrieval operations.
g.V().hasLabel('person').out('knows').values('name')When working with this query, the traversal starts at all vertices with g.V(), positioning each traverser on a different vertex. Then, hasLabel('person') filters these traversers, keeping only those located on vertices with the label "person." From there, out('knows') moves each traverser along outgoing "knows" edges to adjacent vertices. Finally, values('name') extracts the "name" property value from each traverser's current vertex.
Gremlin syntax and operations
After establishing a basic understanding of traversal, we will explore essential Gremlin syntax and operations, using a property graph similar to the one below ‒ a "modern" graph commonly used as an example in TinkerPop.
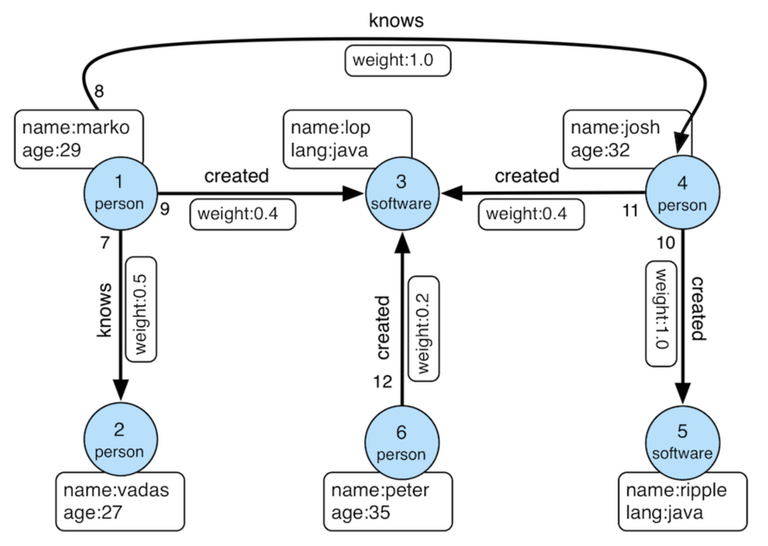
Let’s see a Gremlin query, can you guess the answer?
g.V().has('name','marko').out('knows').values('name')Using the Gremlin console from TinkerPop, you have the opportunity to execute and experiment with the query on your own. We will skip the configuration details of the graph traversal source in order to concentrate on the query aspect.
gremlin> g.V().has('name','marko').out('knows').values('name')
==>vadas
==>joshLet's break down this Gremlin query step-by-step. We start with 'g', which represents our traversal's starting point — the 'modern' graph. V() selects all vertices within this graph. Next, we use has('name', 'marko') to filter these vertices, keeping only the one named 'marko'. This 'has' step acts as a specialized filter in Gremlin.
From there, out('knows') — an extension of the flatMap step — follows the outgoing edges labeled 'knows' from the 'marko' vertex. This leads us to the vertices representing people he knows. Finally, values('name'), a map step, extracts the 'name' property from these vertices. As a result, we see 'vadas' and 'josh' — the names of people Marko knows in the graph.
Let’s see another example.
gremlin> g.V().has('name', 'marko').
> repeat(out('knows').dedup()).
> emit().times(3).dedup().values('name')
==>josh
==>vadasThis query retrieves individuals who are reachable within three steps from Marko via the "knows" relationship. However, due to its limited size, this graph may not fully demonstrate the query's capabilities. The query utilizes a repeat() step, with the times() modifier controlling the loop count, thus eliminating the need for manually chaining the out() steps. The step modulator emit() outputs these vertices after each loop, allowing us to obtain vertices reachable within three steps, but not exactly in three steps. The dedup() step appears twice in the query. The second dedup() removes redundant results, while the first one within repeat() improves query performance as we eliminate a lot of redundancy during the traversal if the engine doesn’t make any optimization here. You can further explore by comparing the performance of this query with and without incorporating dedup() inside the repeat() step on a larger graph. Alternatively, try replacing out('knows') with both() to observe differences in efficiency.
We can change that query a little bit to demonstrate groupCount() step, a step based on map and side effect step.
gremlin> g.V().has('name', 'vadas').
> repeat(both().dedup()).
> emit().times(2).dedup().
> groupCount('m').by(label).values('name')
==>marko
==>lop
==>josh
==>vadas
gremlin> g.V().has('name', 'vadas').
> repeat(both().dedup()).
> emit().times(2).dedup().
> groupCount('m').by(label).values('name').cap('m')
==>map[person:3 software:1]As you see, the groupCount() step looks transparent in the first query but you can use cap() step to retrieve its result stored in the variable m. The groupCount() step is modified by the by() step modulator to count the number of items in the previous results for each label. f you don’t specify a name in the groupCount() step, it will not function as a side effect step.
gremlin> g.V().has('name', 'vadas').
> repeat(both().dedup()).
> emit().times(2).dedup().
> groupCount().by(label)
==>map[person:3 software:1]Advanced Gremlin features
Beyond basic vertex and edge traversal, Gremlin provides advanced features for efficient graph analytics. We'll explore two of these in this section.
Pattern matching
Gremlin queries are fundamentally imperative, providing step-by-step instructions for graph traversal and specifying precise operations at each stage. However, some Gremlin steps, such as match(), introduce a more declarative style by enabling pattern matching within a graph. This allows you to define the relationships you're seeking without explicitly detailing the traversal process.
A key feature of match() is variable binding. By assigning variables within the pattern, you can easily reference specific elements of the matched pattern later in your query, streamlining complex traversals. An example use case for match() is finding interconnected relationships. For example, you might use it to discover users who share interests with their friends.
g.V().match(
__.as('a').out('friends').as('b'),
__.as('a').out('likes').as('c'),
__.as('b').out('likes').as('c')
).select('a', 'b', 'c')This query finds users ('a') who have a friend ('b') that likes the same product ('c') as they do. The match() step allows you to express this complex relationship in a clear, declarative manner.
Graph algorithms with OLAP processing
OLAP (Online Analytical Processing) refers to the batch processing of large volumes of graph data to perform analytical computations. Unlike OLTP (Online Transaction Processing), which handles real-time transactional queries, OLAP is designed for intensive computation over the entire graph or substantial portions of it. Gremlin's OLAP capabilities are built upon the GraphComputer abstraction, which allows for the execution of graph algorithms in a distributed and parallelized manner. This abstraction integrates with various graph computing systems like Apache Spark, Apache Giraph, and Hadoop, enabling scalability and performance optimizations.
Gremlin offers a range of built-in algorithms that are essential for graph analysis. These include popular algorithms like PageRank, Connected Components, and Shortest Path. These algorithms can be easily implemented and executed on large-scale graphs using the OLAP processing capabilities. Here's a SparkGraphComputer example executing the PageRank algorithm (configuration and imports omitted for brevity):
g.withComputer(SparkGraphComputer).V().pageRank().by('rank')By calling withComputer(SparkGraphComputer), Gremlin is instructed to execute the traversal in OLAP mode using Apache Spark. The pageRank() step runs the PageRank algorithm, which computes the importance of each vertex based on the structure of the graph. The by('rank') modulator specifies that the resulting PageRank values should be stored in a vertex property named 'rank'.
Practical examples and use cases
Just as other graph query languages, Gremlin can be used to solve a wide variety of real-world problems that involve complex relationships between data points. Let's explore some practical examples and use cases.
Social Network
Social network analysis is indeed a great practical example. You can refer to the LDBC’s Social Network Benchmark to see many real-world queries. We will demonstrate a slightly simplified friend recommendation query to give you a taste of how Gremlin can be used in this domain.
Suppose we want to perform a friend suggestion analysis. Given a specific tag (e.g., "sports"), we want to identify pairs of people who are not currently friends but share at least one common friend and both have an interest in the given tag.
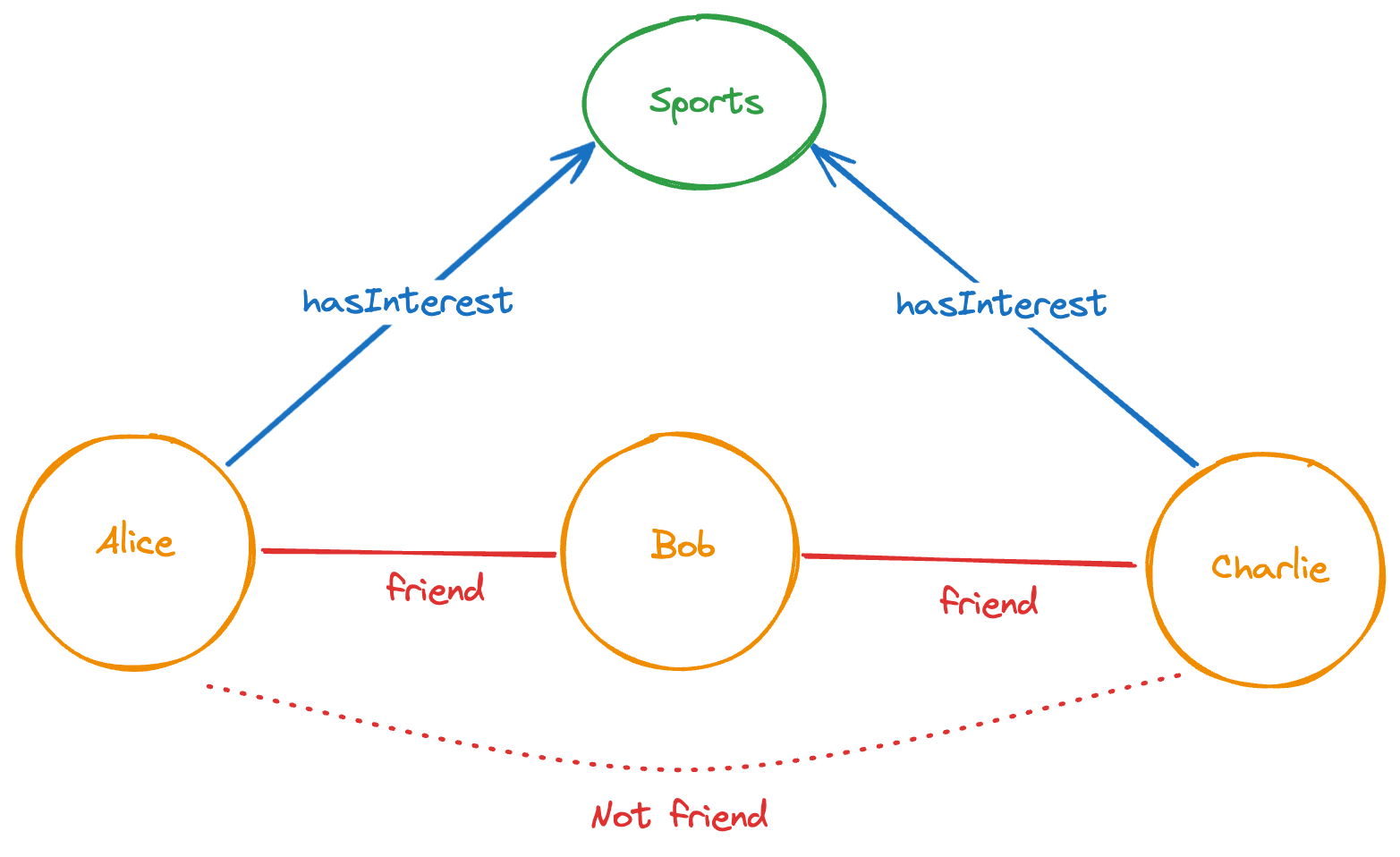
Below is a Gremlin query that accomplishes this task using a pattern matching technique.
g.V().match(
__.as('a').both('friend').as('b'),
__.as('b').both('friend').as('c'),
__.as('a').out('hasInterest').has('tag', 'name', 'Sports').as('x'),
__.as('c').out('hasInterest').as('x'),
__.not(__.as('a').both('friend').as('c'))
).where('a', lt('c')).dedup('a','c').
project('person1', 'person2').
by(select('a').by('name')).
by(select('c').by('name'))We can also write the query in a more traversal-style Gremlin.
g.V().has('tag', 'name', 'Sports').as('x').
in('hasInterest').as('a').
select('x').in('hasInterest').as('c').where(gt('a')).
both('friend').as('b').both('friend').where(eq('a')).
not(__.both('friend').where(eq('c'))).dedup('a', 'c').
project('person1', 'person2').
by(select('a').by('name')).
by(select('c').by('name'))Financial transaction
Graph-based data management is common and useful in the financial world. For a comprehensive understanding of its applications, you can refer to the LDBC’s Financial Benchmark.
Let's consider a practical example query. Given a specific account as the destination, we want to find all incoming transfers where the amount exceeds a predefined threshold within a specific time range (between startTime and endTime). The query should return the total number of transfers and the sum of their amounts.
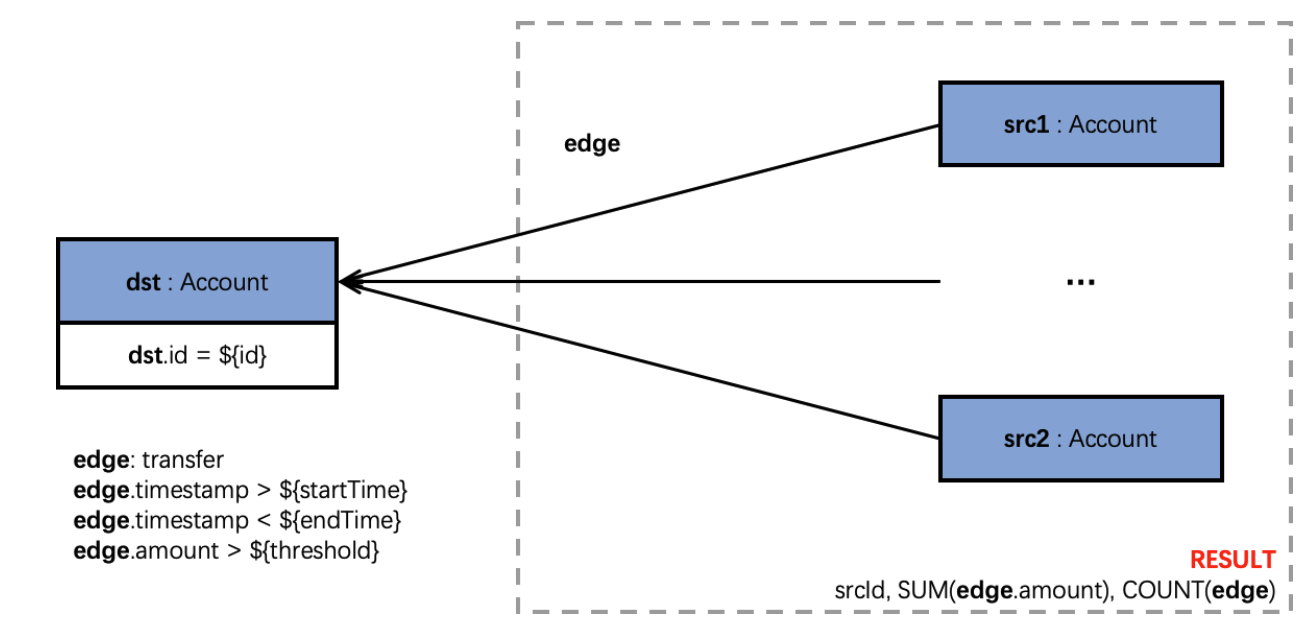
g.V($dst).inE('AccountTransferAccount').
has('createTime', between($startTime, $endTime)).
has('amount', gte($threshold)).
group().by(outV()).unfold().
project('srcId', 'numEdges', 'sumAmount').
by(select(keys).id()).
by(select(values).unfold().count()).
by(coalesce(select(values).unfold().values('amount').sum(), constant(0))).
order().by('sumAmount', desc).by('srcId', asc)Using Gremlin with PuppyGraph
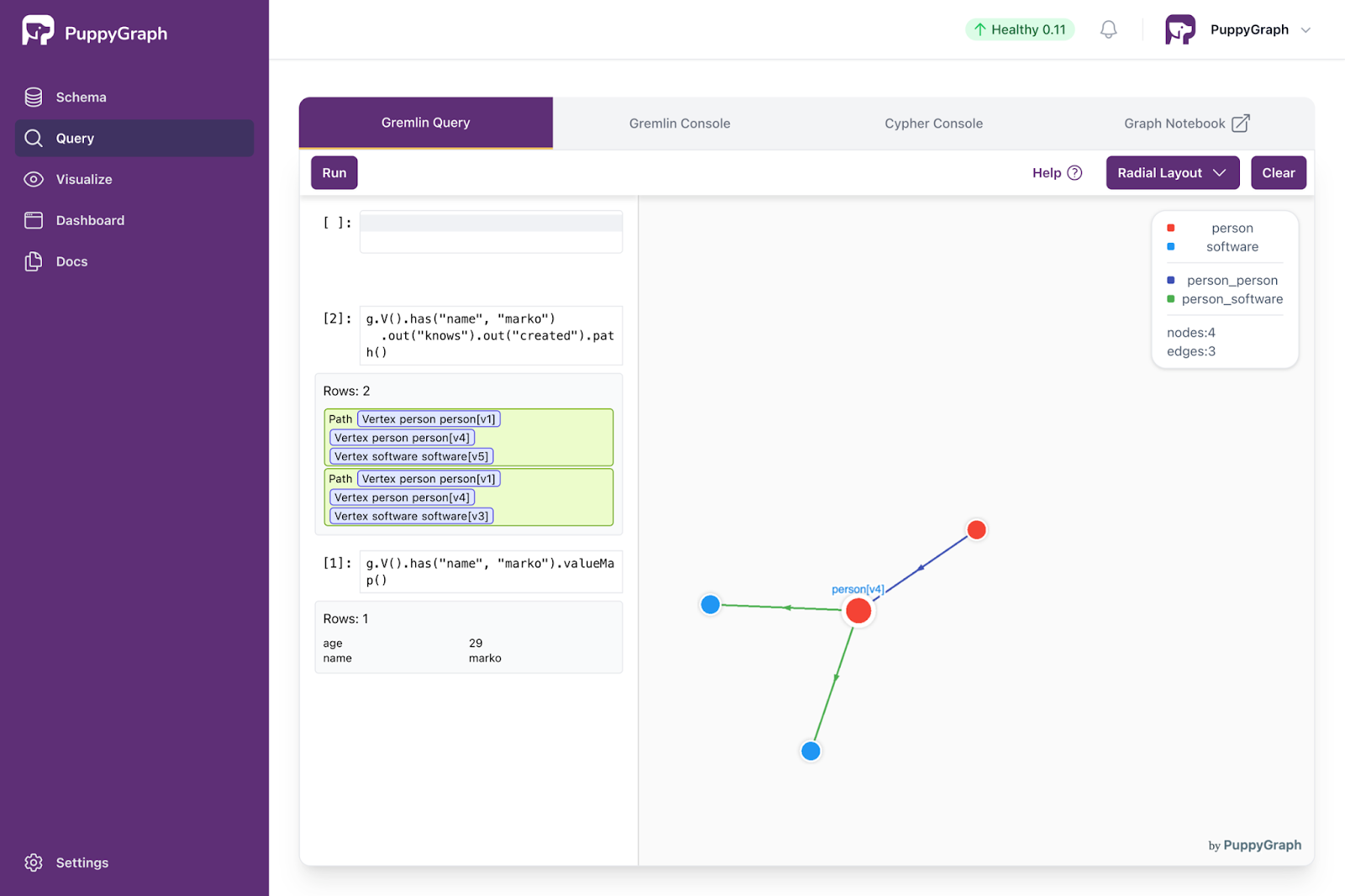
PuppyGraph offers a unique advantage by supporting Gremlin queries without the need for a dedicated graph database. This flexibility allows users to query relational data with Gremlin, bypassing traditional ETL processes and simplifying the use of graph traversal techniques. PuppyGraph supports a variety of data sources, and this support is continually expanding. After connecting to your chosen data source and submitting your graph schema, you can write Gremlin queries and view the results in various ways.
You can utilize the interactive query interface to execute queries and view the outcomes in multiple formats, such as visualizations, for a comprehensive understanding. PuppyGraph also offers an interactive CLI and graph notebooks for querying. Additionally, you can connect through client drivers in various programming languages. If you're familiar with the Gremlin console from Apache TinkerPop, you can also use it to connect to PuppyGraph. See this page for more information.
PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


Conclusion
Gremlin offers a powerful, flexible approach to querying and traversing graph data. Its functional, data-flow language design allows users to express complex queries on property graphs efficiently. By understanding Gremlin's core concepts like graph structure, traversal, and steps, developers can leverage its capabilities for various applications, from social networks to financial analysis. Gremlin's versatility is further enhanced by its support for both imperative and declarative querying styles, as well as its ability to handle large-scale graph processing through OLAP capabilities. And now, PuppyGraph empowers users to run Gremlin queries directly on relational data, eliminating the need for traditional ETL processes and providing flexible tools for interactive querying and data visualization.
Interested in trying PuppyGraph? Start with our forever-free Developer Edition, or try our AWS AMI. Want to see a PuppyGraph live demo? Book a call with our engineering team today.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.


