
What Is Graph Database?

This article will explore how graph databases work, their main types, and their advantages. We’ll also look at key use cases and challenges, as well as popular graph database technologies shaping this evolving landscape.
What is a graph database?
A graph database is an online database management system that uses a graph data model to represent and store data. It offers Create, Read, Update, and Delete (CRUD) operations that allow users to interact with the data seamlessly. Unlike relational databases, graph databases excel at handling interconnected data, making them ideal for applications like social networks, recommendation engines, and fraud detection.
How graph databases work
Graph databases operate on graphs. A graph is a data structure that represents objects and their relationships. These objects are called nodes, and the connections between them are edges. For example, in a social network, people are nodes, and friendships are edges. Nodes and edges can have labels (like "student") and properties (like age or location), which add more information to the graph. This allows graphs to capture complex relationships in a way that's easy to understand and analyze.
In graph theory, the focus is typically on identifying meaningful patterns or connections within a graph. For example, a common subgraph pattern might involve finding a "friend of a friend" in a social network, revealing indirect relationships. On the other hand, some applications require global insights across the entire graph, such as determining a web page's importance through PageRank.

Graph databases are specialized database management systems that operate using a graph-based data model. In these databases, both nodes and edges are considered primary entities, meaning they are fundamental elements of the data model, unlike in traditional relational databases where relationships are expressed implicitly through foreign keys. This explicit treatment of relationships allows for easier and more efficient querying and exploration of connected data.
To interact with a graph database, users leverage specialized graph query languages tailored for graph structures, such as Cypher and Gremlin. These languages enable two key styles of querying: pattern matching and graph traversal. Pattern matching focuses on identifying specific subgraphs that meet certain criteria, while graph traversal involves navigating through the graph step-by-step to discover connections. We will see some query examples later.
While the technical implementation of graph databases may vary, the essential goal remains the same: to expose the data as a graph to the user. Some graph databases store nodes and edges directly as discrete entities, while others may utilize relational databases or NoSQL solutions under the hood. These design choices influence factors such as performance, scalability, and cost. However, regardless of the underlying technology, the key requirement is that the database presents the data to users as a graph, facilitating intuitive exploration and analysis of relationships.
What are the types of graph database
As we've seen, graph databases are characterized by their external interface, which presents a graph data model and operations. Now, let's delve deeper into their internal workings, examining the graph data model and the underlying storage engine.
Graph data models
We will see two prominent graph data models here: property graphs and RDF. Property graphs are the prevailing model in graph databases, favored for their flexibility and intuitive structure. In contrast, RDF was developed to support the semantic web's vision of interconnected data, enabling machines to reason and infer new knowledge.
Property Graphs
A Property Graph, particularly the Labeled Property Graph, models data as nodes, relationships, and properties. Each node or relationship can have labels and attributes (key-value pairs), making it highly flexible for storing complex relationships.
- Nodes represent entities (like users, products, or places).
- Edges represent relationships between these entities (like “FRIEND_OF” or “PURCHASED”).
- Properties capture additional information, such as a user’s age or the timestamp of a transaction.
Labeled Property Graphs allow multiple types of nodes and relationships, and the schema can evolve over time, offering more freedom compared to traditional relational databases.
Graph query languages such as Cypher (used in Neo4j) and Gremlin (used in Apache TinkerPop) are tailored to interact with Property Graphs.
- Cypher: A declarative language that focuses on pattern matching. It enables developers to express graph traversal queries intuitively, using patterns like (user)-[:FRIEND_OF]->(anotherUser).
- Gremlin: A procedural language that allows developers to express graph traversal steps explicitly as a chain of steps.
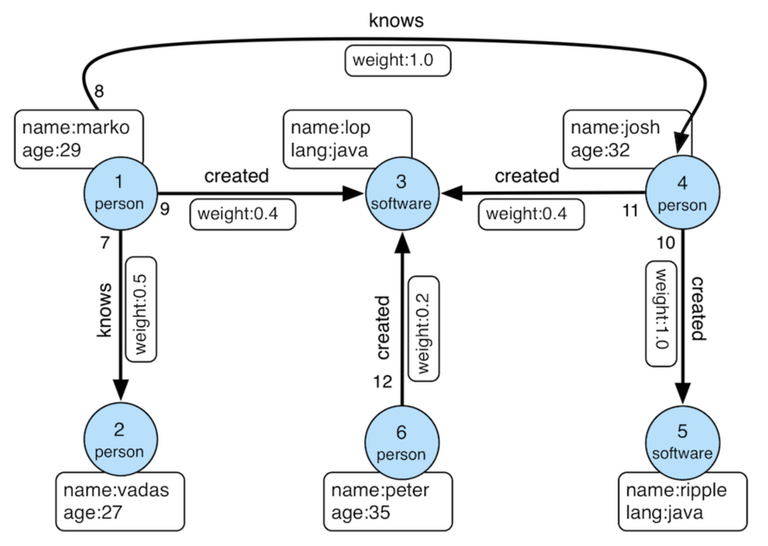
The figure is an example graph used by Apache TinkerPop called ‘modern graph’. Below is an example demonstrating how to find a pair of people Marko knows, using both Cypher and Gremlin query languages. The result of the queries should be (marko, josh, vadas).
Resource Description Framework (RDF)
The Resource Description Framework (RDF) is a standard for representing data, based on the entity-relationship model. In RDF, data is represented as a set of triples, each taking one of these two forms:
- (ID, attribute-name, value)
- (ID1, relationship-name, ID2)
Here, ID, ID1, and ID2 are identifiers for entities, which RDF also refers to as "resources." Within a triple, the first element is the subject, the second is the predicate, and the third is the object. This gives us the basic structure: (subject, predicate, object).
This structure lends itself naturally to a graph representation. Entities and attribute values become nodes in the graph, while attribute names and relationships become edges connecting those nodes. The attribute or relationship name serves as the label for the edge.
RDF was invented to address the need for a standardized way to describe data and metadata on the web, enabling data to be understood and processed by machines. Representing information using this RDF graph model (or its variations and extensions) is what we call a knowledge graph.
To query RDF data, we use SPARQL, which is a W3C standard to query RDF data. SPARQL allows users to match patterns in the RDF graph, similar to SQL but adapted for triples. A simple SPARQL query to find all people Alice knows might look like:
SELECT ?person
WHERE { <Alice> <knows> ?person . }Storage and engine
Here we just divide storage and engine classifications into two categories simply: native and non-native. Although some argue that graph databases should exclusively use native storage for optimal performance and scalability, others believe that non-native storage systems can still be effective, especially when combined with robust indexing mechanisms and other optimizations.
Native storage and engine
Native storage refers to a method of storing data where the graph's fundamental elements—nodes (vertices) and edges (relationships)—are represented directly as first-class entities in the database. In a native storage system, each node inherently knows about its adjacent edges, allowing the system to access and traverse these edges directly without needing to perform additional lookups through an index.
A native graph engine, therefore, benefits from being able to directly reference and follow the edges connected to a node, which eliminates the need to query an index structure. This "index-free adjacency" model enables highly efficient graph traversals, as it removes the logarithmic overhead commonly associated with index lookups. Also, the time taken to execute a traversal query—such as moving from one node to a connected node is constant (O(1)) and does not depend on the overall size of the graph, which enables excellent scalability.
Non-native storage and engine
Non-native graph storage and processing engines employ a range of storage techniques to organize and manage data, ultimately presenting it as a graph-like structure for querying and analysis. Instead of storing data in an inherently graph-based format, these systems serialize graph data into relational databases, object-oriented databases, or other types of general-purpose data stores, such as key-value or document databases. This approach allows them to leverage advancements in relational and NoSQL databases, as well as parallel and distributed computing techniques.
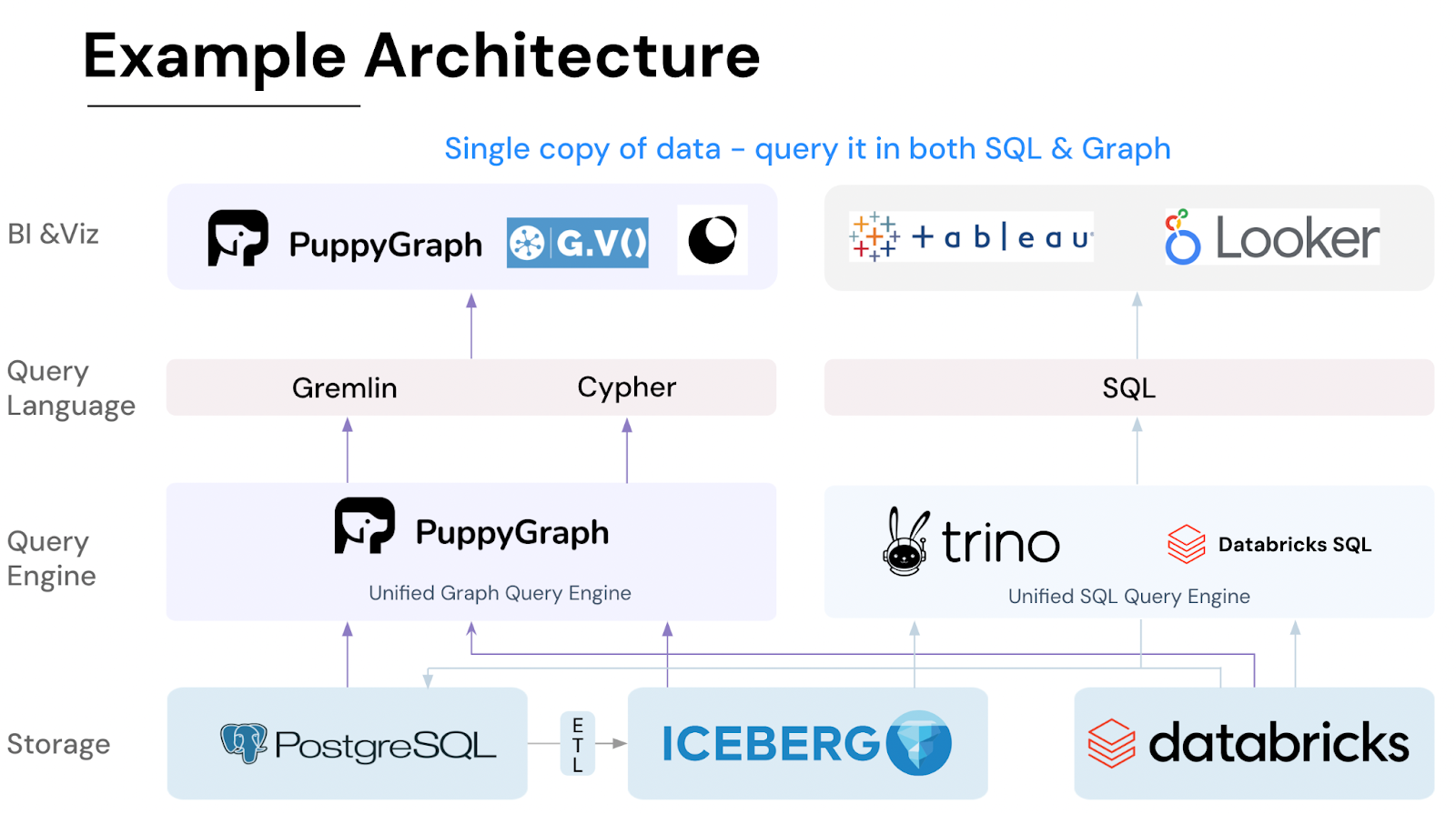
Besides, non-native approaches may offer advantages in terms of integration with existing systems or flexibility in handling different types of data beyond graph structures. This expands the potential of the database to encompass a wide range of data modalities. Here is the example architecture of PuppyGraph, where you can see that both SQL and graph query language are accepted.
What are the benefits of graph database
Now that we have a basic understanding of graph databases, let's explore the advantages they offer when working with graph data. Here are some key benefits that make graph databases a powerful tool for modern data needs.
Performance
Graph databases excel at performance, especially when it comes to handling complex and highly interconnected data. They are optimized for executing graph traversal queries, which would be inefficient in traditional relational or NoSQL databases. Vendors take different approaches to achieving this performance. For instance, some, like Neo4j, use native graph storage and processing engines, while others leverage relational or NoSQL databases as the underlying storage. Additionally, modern graph databases often take advantage of parallel computing, distributed processing, and batch operations to enhance performance. Regardless of the methods, vendors consistently demonstrate strong performance in benchmarks, showcasing the efficiency of graph databases for intricate queries and large-scale data.
Convenience
One of the most significant advantages of graph databases is their support for specialized graph query languages, such as Gremlin and Cypher. These languages are designed to handle complex graph patterns and relationships seamlessly. Writing queries becomes more straightforward and mirrors the way we naturally think about relationships and connections in data. In contrast, crafting equivalent queries in SQL for relational databases can be cumbersome and less intuitive, often requiring intricate joins and subqueries that are harder to write and maintain.
Scalability
Graph databases are designed to scale alongside growing datasets and increasingly complex relationships. They can efficiently handle large volumes of data without significant degradation in performance. Some graph databases support horizontal scaling by distributing data across multiple servers or clusters, allowing them to manage vast and intricate networks of data. This scalability ensures that as your data grows, the database can accommodate increased loads while maintaining fast query response times. This makes graph databases suitable for big data applications and real-time analytics where performance and scalability are critical.
PuppyGraph is proven for enterprise-level scale, and is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


Built-in graph algorithms
Many graph databases come equipped with a suite of built-in graph algorithms that facilitate advanced analytics and operational tasks (OLAP jobs). These algorithms can perform functions like shortest path calculations, community detection, and centrality measures directly within the database. This integration simplifies the process of conducting graph analyses, as there's no need to export data to external tools or write custom algorithms. It enables users to derive insights more efficiently and apply complex analyses to their data with ease.
Additional graph tools
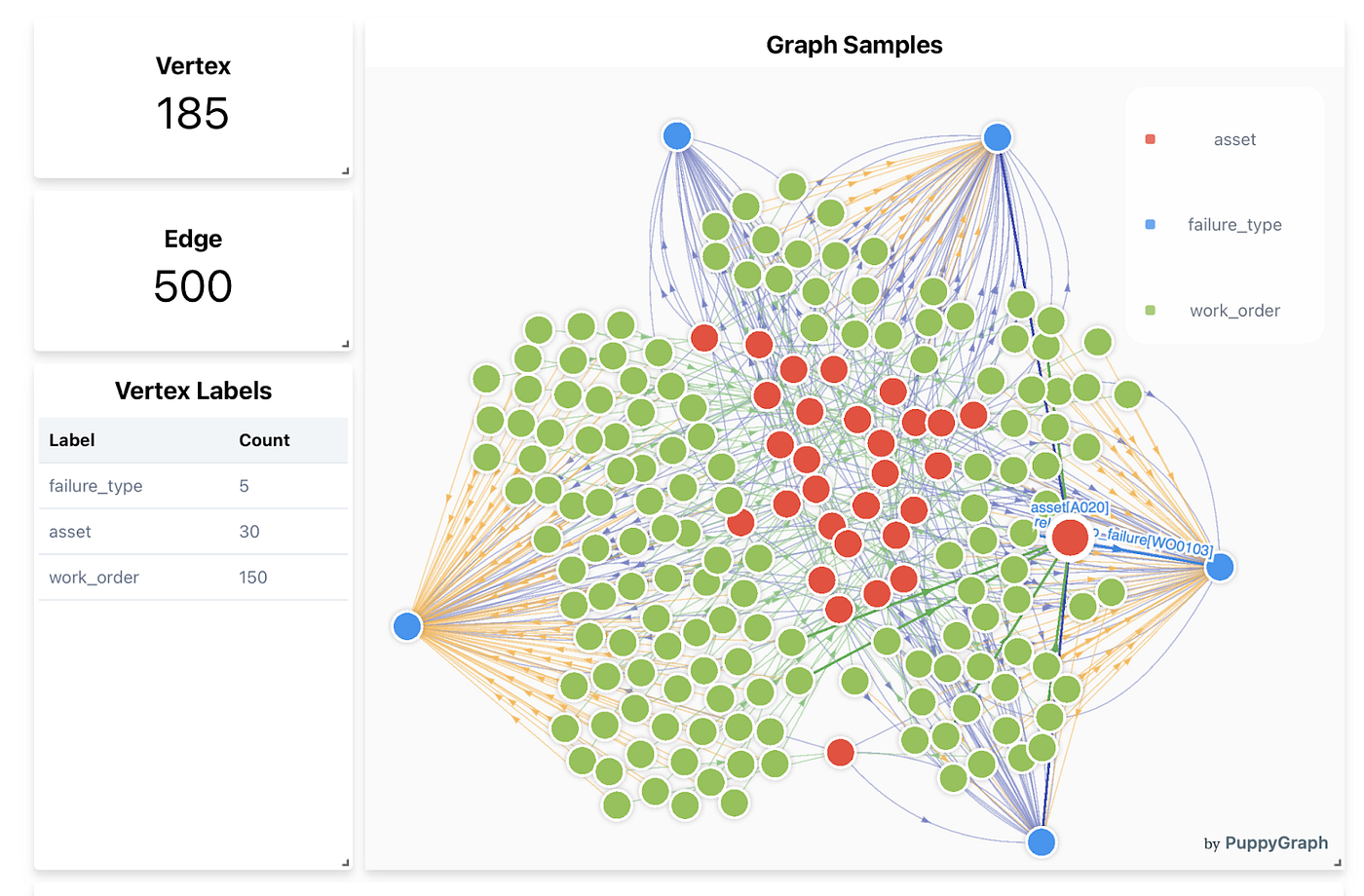
Beyond querying and analytics, graph databases often offer supplementary tools such as visualization interfaces. These tools allow users to create graphical representations of their data, making it easier to comprehend complex relationships and spot patterns or anomalies. Visualization enhances the user experience by providing an accessible way to interact with the data, which is particularly beneficial for stakeholders who may not be familiar with query languages. This added layer of usability makes graph databases more approachable and easier to work with.
What are the challenges of graph database
Graph databases offer significant advantages when dealing with highly interconnected data, but they also introduce unique challenges that organizations must consider when managing and scaling these systems.
Performance and scalability
One of the primary challenges of managing graph databases is ensuring optimal performance and scalability, especially when dealing with very large datasets. Due to the inherently interconnected nature of graph data, queries often involve traversing multiple nodes and edges, which can result in complex operations that are difficult to optimize. The performance of a query often depends heavily on how it is written and on a deep understanding of the graph structure itself.
Additionally, scaling a graph database across distributed systems presents its own difficulties. Sharding is particularly tricky with graphs because data is tightly interconnected. Partitioning a graph across multiple servers can lead to high-latency operations, particularly when queries need to traverse multiple partitions. Cross-partition queries can also introduce additional overhead, complicating the process of achieving both performance and scalability.
Integration and migration
Integrating a graph database into existing systems or migrating data from traditional relational databases often proves to be a complex and error-prone process. Extract, Transform, Load (ETL) workflows can introduce several pain points, as data in relational databases is typically structured in rows and tables, while graph databases require a more flexible, node-and-edge format. During the ETL process, errors can arise, especially when translating relationships between entities in a way that graph databases can efficiently process.
Furthermore, ensuring that graph databases coexist with other types of databases or legacy systems requires careful planning. Integration may demand significant custom work to ensure compatibility and seamless data flow between systems.

Data modeling and schema design
Many graph databases offer a schema-less design, which gives users flexibility to store various kinds of relationships and data points. However, this lack of a formal schema can lead to inconsistencies, especially in large and dynamic datasets. Without a well-defined schema, it becomes harder to ensure data quality and consistency, leading to potential issues when scaling up or conducting complex queries.
Another challenge is dealing with dynamic topologies. In real-world applications, the structure of a graph often changes over time as new types of nodes, edges, or attributes are introduced. Designing a schema that can adapt to these changes without negatively impacting query performance is a difficult task. Evolving schemas must balance flexibility with efficiency, making sure the database can grow while still allowing for performant queries on increasingly complex graphs.
Graph database use cases
When graph data is valuable, graph databases can come into play. Let's explore some prominent use cases that showcase the power and versatility of graph databases.
Social networks
In social networks, relationships between users are foundational. Graph databases naturally fit this model by treating users as nodes and their connections (such as friendships, follows, or interactions) as edges. This enables efficient queries to discover mutual friends, suggest new connections, or analyze community structures in a way that scales with the ever-growing volume of social data.
Graph databases also allow real-time insights, such as identifying influencers, finding tightly knit groups, and even recommending content by analyzing user behavior. Their ability to track and explore these complex relationships helps platforms enhance user engagement and build smarter recommendation engines.

Financial network monitoring
In financial services, detecting anomalous patterns is crucial, particularly for monitoring transaction flows and preventing illicit activities. Instead of focusing solely on fraud detection, graph databases help in financial network monitoring, which can include spotting complex money-laundering schemes, uncovering hidden relationships in transaction networks, and identifying suspicious patterns across institutions.
The power of a graph database lies in its ability to trace indirect connections between entities and flag suspicious relationships that traditional methods might overlook. By visualizing and querying these transactional networks, financial institutions can stay ahead of potential risks and better ensure regulatory compliance.

Cybersecurity
In cybersecurity, understanding the intricate web of devices, users, and behaviors is essential to uncovering and mitigating threats. Graph databases offer a dynamic and highly scalable way to track relationships between IP addresses, devices, and communication paths.
For example, they can help security teams quickly identify and isolate compromised nodes within a network or trace the path of an attack as it spreads across different systems. This capability enhances threat intelligence, allowing for rapid response and proactive defense mechanisms against cyber threats.

Conclusion
Graph databases are revolutionizing how we manage and analyze interconnected data. They offer efficient ways to model complex relationships, outperforming traditional relational databases in scenarios where data points are highly linked. However, challenges like performance optimization and integration with existing systems can arise. Tools like PuppyGraph help overcome these obstacles by enabling you to work with relational data in a graph-like manner without complex migrations or ETL processes.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.


