

7 Best Graph Databases in 2026

As we enter 2026,the demand for graph databases remains strong, driven by the increasing need to analyze and understand complex data relationships. Businesses continue to seek effective ways to extract insights from interconnected information, and graph databases excel in handling these challenges. Their ability to map and query intricate networks makes them valuable for applications like social networks, recommendation systems, and data security.
This guide highlights seven graph databases to consider in 2026, each suited to different use cases and scalability requirements. From well-known options like Neo4j and AWS Neptune to newer choices like PuppyGraph, these databases provide distinct strengths in data management, query capabilities, and integration. Whether you need real-time analytics, large-scale processing, or compatibility with existing systems, this list offers solutions to work effectively with connected data.
What is a graph database?
A graph database is a specialized type of database management system that uses graph theory to store, represent, and query data. Unlike traditional relational databases that may struggle with complex relationships, graph databases are designed to handle interconnected data efficiently. They model data as a network of nodes (entities) and edges (relationships), making them particularly well-suited for applications that involve complex relationship patterns, such as social networks, recommendation engines, and fraud detection systems.
In a graph database, the primary focus is on the relationships between data points. This relationship-centric approach allows for more natural modeling of real-world scenarios where connections between entities are just as important as the entities themselves. For example, in a social network, individuals are represented as nodes, and the friendships between them are represented as edges. This structure makes it easy to query complex relationship patterns, like finding a "friend of a friend," which illustrates a common subgraph pattern in such networks.

Graph databases support standard Create, Read, Update, and Delete (CRUD) operations, enabling seamless interaction with the data. They utilize specialized query languages like Cypher and Gremlin, designed specifically for pattern matching and graph traversal. These languages allow users to perform complex queries that would be inefficient or cumbersome in a traditional relational database.
How does a graph database work?
Graph databases work by representing data as a network of nodes and edges, where nodes are the entities or objects, and edges are the relationships connecting them. Both nodes and edges can have labels and properties that provide additional context and meaning. This flexible data model allows for multiple node and relationship types and supports evolving schemas, making it adaptable to changing data requirements.
There are two main types of graph databases based on their data models:
- Property Graphs: This is the most common type of graph database. Property graphs use nodes, relationships, and properties to model data. They offer a high degree of flexibility, allowing for multiple node and relationship types and an evolving schema. Query languages like Cypher and Gremlin are commonly used with property graphs. These languages are powerful tools for querying and manipulating the data, enabling complex pattern matching and graph traversal operations.
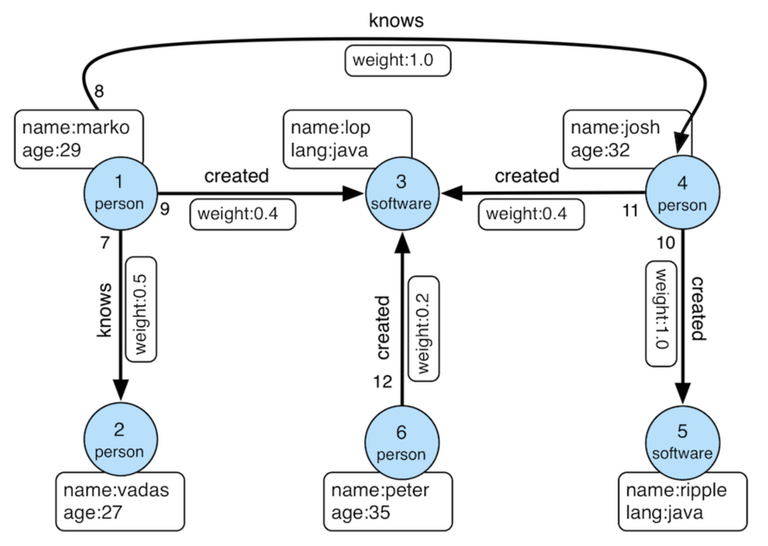
- RDF (Resource Description Framework) Graphs: RDF graphs represent data in triples, either as (ID, attribute-name, value) or (ID1, relationship-name, ID2). Based on the entity-relationship model, RDF is often used in knowledge graphs and semantic web applications. SPARQL is the standard query language for querying RDF data, allowing for intricate queries over large datasets.
Graph databases can also be categorized based on their storage mechanisms:
- Native Graph Databases: These databases store nodes and edges directly as first-class entities. This approach allows for efficient traversal and scalability due to "index-free adjacency," meaning that connected nodes physically point to each other in the database, eliminating the need for index lookups during traversal.
- Non-Native Graph Databases: In contrast, non-native graph databases serialize graph data into other database formats like relational or NoSQL databases but present the data as a graph. This method leverages existing database technologies while providing the benefits of a graph model. An example of this approach is PuppyGraph, which allows users to query relational data as a graph without the need for ETL (Extract, Transform, Load) processes. This highlights a practical application of graph database concepts, providing flexibility and ease of integration with existing relational data.
The growing importance of graph databases stems from their ability to handle complex relationships and provide insights into connected data. They are becoming essential tools for businesses dealing with large, interconnected datasets, enabling them to uncover hidden patterns and make more informed decisions. However, implementing graph databases comes with challenges. Performance optimization requires careful consideration of data modeling and schema design to ensure efficient querying and scalability.
Key factors to consider when selecting a graph database
Choosing the right graph database for your application is a critical decision that can significantly impact the performance, scalability, and success of your project. With various options available, it's essential to consider several key factors to ensure you select a database that aligns with your specific needs.
Performance
Performance is one of the most crucial factors to evaluate when selecting a graph database. It encompasses how efficiently the database handles data storage, retrieval, and complex query execution. Assess the database's ability to perform rapid graph traversals, pattern matching, and real-time analytics. Consider factors such as latency, throughput, and concurrency support. The underlying architecture, indexing mechanisms, and optimization features of the database can greatly influence its performance. It's important to choose a graph database that meets the performance demands of your application, ensuring swift response times and a seamless user experience.
Scalability
One of the foremost considerations is scalability. As your data grows, the graph database must efficiently handle increasing volumes without compromising performance. The scalability of native graph databases is often debated and is a focal point among vendors, highlighting its importance. Assess whether the database can manage not only your current data load but also accommodate future growth. Consider factors like horizontal and vertical scaling capabilities, distributed computing support, and how the database handles extensive graph traversals. Understanding these aspects will help you choose a database that remains robust as your application evolves.
Processing requirements
Understanding the processing needs of your application is crucial. Graph databases are generally categorized into OLTP (Online Transaction Processing) and OLAP (Online Analytical Processing) systems. OLTP graph databases are optimized for handling numerous transactions involving small amounts of data, making them ideal for real-time applications like social networks and recommendation engines. OLAP graph databases, on the other hand, are designed for complex analytical queries over large datasets, suitable for tasks such as fraud detection and data mining. Although these categories are rapidly converging, with many vendors offering solutions capable of handling both, identifying your primary processing requirements will help narrow down your options.
Documentation and support
Comprehensive documentation is another vital aspect to consider. Detailed documentation enhances the utilization of a graph database by providing in-depth information about its structure, schema design, query language, and best practices. It serves as a valuable resource for developers and administrators, easing the learning curve and facilitating smoother implementation and management. Additionally, consider the level of community and vendor support available. Active communities and responsive vendor support can be invaluable for troubleshooting and staying updated with the latest features and security patches.
Testing with real data
Before making a final decision, it's highly recommended to test the selected graph database with real data and queries relevant to your application. This practical approach is essential for verifying the database's performance under your specific workload and use cases. Testing can reveal how the database handles data ingestion, query execution times, and concurrency under real-world conditions. It also provides insights into the usability of the database, the efficiency of its query language, and any potential issues that may not be apparent during initial evaluations.
Additional considerations
Beyond these primary factors, consider other elements such as compatibility with your existing technology stack, the learning curve associated with the database's query language, licensing costs, and the availability of enterprise features like security and backup solutions. Evaluate whether the database supports open standards and interoperability with other systems, which can be crucial for long-term flexibility and integration.
7 best graph databases of 2026
With the basics of graph databases covered, it’s time to explore the seven leading graph databases tools of 2026 in detail. Here’s a closer look at what makes each of these options stand out:
PuppyGraph

PuppyGraph stands out as a cutting-edge distributed graph solution designed for ease of use, scalability, and high performance. It is the first and only graph query engine in the market. Unlike other graph database solutions that require extracting, transforming, and loading (ETL) data from existing databases, PuppyGraph directly integrates with your existing relational data sources. You don’t have to maintain complex data pipelines and incur latency costs. These strengths make PuppyGraph ideal for fast-paced environments and real-time analytics.
- Pros:
- Query your relational database as a graph without additional ETL processes
- High performance for complex queries
- Integrates seamlessly with Iceberg, Delta Lake, Hive, PostgreSQL, and more
- Support popular graph query languages Gremlin and Cypher
- Cons:
- The documentation could be more comprehensive, as it occasionally lacks updates on the latest features
- Cannot modify data via graph queries (as it's actually not a graph database)

PuppyGraph is not a graph database, but a tool that lets you query and visualize your relational data in a graph format.
- It enables users to query tables as graphs on existing data, eliminating the need for additional ETL processes, which can save time and resources.
- With its architecture built on top of relational data stores, it provides scalable analytics and exceptional performance, especially on large datasets.
- PuppyGraph is technically a graph query engine rather than a full-fledged database. This may be limiting for those specifically looking for a dedicated graph database but offers unique advantages for users looking to implement graph analytics on top of existing tables.
Best Suited For: Organizations that want to gain graph-based insights directly from their existing data lakes or warehouses.
AWS Neptune

- Pros:
- Neptune is fully managed by AWS, handling tasks such as backups, patching, and scaling, which reduces operational overhead for users
- Optimized for storing billions of relationships
- Integration with AWS Ecosystem: Neptune integrates seamlessly with other AWS services, facilitating data ingestion, analytics, and security management.
- Supports both property graph (Gremlin/openCypher) and RDF (SPARQL)
- Cons:
- Pricing can be high for large datasets
- Establishing connections to Neptune clusters across different VPCs can be challenging. Users have explored solutions like using a transit gateway to bridge VPCs, but this approach requires careful configuration to ensure connectivity and security
- High write or read loads can lead to request throttling. Neptune has specific concurrency limits, and exceeding these can result in throttling exceptions, necessitating careful workload management and optimization.
- Limited customization options compared to self-hosted solutions
Amazon Neptune is a purpose-built, fully managed graph database service that provides high availability, security, and integration within the AWS ecosystem. It supports both property graph and RDF models, making it versatile for different graph use cases while maintaining ACID compliance and immediate consistency.
Best Suited For: Applications requiring robust, large-scale graph database support within the AWS ecosystem with a relatively large project budget.
TigerGraph

- Pros:
- Real-time processing and scalability
- Designed to scale horizontally, accommodating growing data volumes and query demands. This scalability is beneficial for applications requiring extensive graph computations
- Support advanced analytics capabilities, including deep link analysis and pattern matching, which are essential for applications like fraud detection and recommendation systems
- Allows for real-time data updates and querying, making it suitable for dynamic environments where data changes frequently
- Cons:
- While available as a cloud service (TigerGraph Cloud), does not fully embrace a cloud-native architecture where compute and storage are decoupled
- Costs can rise significantly for large-scale applications, as handling large datasets often requires maintaining idle machines that cannot be easily scaled down
- TigerGraph uses a proprietary query language (GSQL). It may require users to invest time in learning and adapting, particularly if they are accustomed to other query languages
TigerGraph offers a powerful solution for large-scale graph analytics with high performance and scalability. However, potential users should be prepared to navigate complexities in data modeling and the learning curve associated with its proprietary query language.
Best Suited For: Enterprise organizations with substantial budgets requiring high-performance graph analytics, deep link analysis, and real-time insights on large-scale connected data.
Neo4j

- Pros:
- Probably the most popular graph database
- Extensive community support and documentation
- Native graph processing
- Flexible Cypher query language
- Its schema-less nature allows for adaptable data models, accommodating evolving datasets without rigid structures
- Cons:
- While Neo4j handles moderate to large datasets efficiently, it can encounter performance challenges with extremely large graphs, particularly during intensive data ingestion or highly complex queries involving deep traversals. Proper use of indexing, query optimization, and partitioning can mitigate these issues but may require significant expertise.
- Neo4j stores properties directly within its graph structure, which can become inefficient when dealing with very large properties, such as lengthy text or binary data. For such cases, offloading large properties to external storage solutions is recommended to maintain performance and storage efficiency.
- Enterprise features can be expensive
- Complex cluster configuration in distributed setups
Neo4j is a popular choice for those new to graph databases as well as experienced developers. Known for its supportive community and comprehensive documentation, Neo4j facilitates efficient querying and storage of connected data.
Best Suited For: Developers and businesses needing a well-supported graph database.
ArangoDB

- Pros:
- Multi-model support (document, graph, key-value), and can simplify application architecture by reducing the need for multiple databases.
- Unified query language (AQL): AQL is a powerful and expressive query language that enables complex queries across different data models, providing a unified approach to data retrieval
- High performance with fault-tolerance and scalability
- Cons:
- Can be memory-intensive, especially when handling large datasets or complex queries.
- The multi-model nature and the specifics of AQL may present a steeper learning curve for newcomers compared to more traditional databases.
- Enterprise edition may be costly for smaller businesses
- While ArangoDB has a growing ecosystem, it may not be as extensive as those of more established databases, potentially limiting the availability of third-party tools and integrations.
ArangoDB is a versatile multi-model database that offers document, graph, and key-value data models within a single platform. This flexibility makes it an ideal solution for applications needing more than just a graph model.
Best Suited For: Applications needing multi-model support and a unified query approach for diverse data requirements.
NebulaGraph

- Pros:
- Able to process complex queries efficiently, even with large datasets. Its distributed architecture allows for parallel processing, which enhances performance
- Optimized for highly connected, unstructured data
- Offers in-memory processing and native graph storage for enhanced query performance.
- Supports advanced analytics capabilities, including deep link analysis and pattern matching, which are essential for applications like fraud detection and recommendation systems
- Allows for real-time data updates and querying, making it suitable for dynamic environments where data changes frequently.
- Cons:
- Uses a proprietary query language, nGQL, which may require time and effort to learn for those accustomed to standard query languages like Cypher or Gremlin.
- Requires technical expertise for deployment and maintenance
- Has fewer third-party integrations and tools compared to more established graph databases like Neo4j or Amazon Neptune
NebulaGraph is designed specifically for handling highly connected data at scale. With its in-memory cache and distributed architecture, it’s ideal for large, complex datasets requiring fast query execution.
Best Suited For: Large-scale distributed systems dealing with highly interconnected data.
Dgraph

- Pros:
- Open-source, distributed graph database designed for high performance and horizontal scalability.
- Supports real-time analysis and offers robust schema-based data modeling through GraphQL.
- Cons:
- Steeper learning curve due to distributed architecture and schema design requirements.
- Limited advanced graph analytics or algorithm support out of the box.
- Smaller community compared to more established graph databases, though it has active forums and documentation.
Dgraph is a powerful distributed graph database, ideal for real-time analytics and managing complex relationships in graph data. Its GraphQL support makes it accessible to developers familiar with this query language, but it may require additional resources and expertise for large-scale deployments or specialized analytics.
Best Suited For: Projects needing a high-performance, distributed graph database with strong real-time analytics capabilities and native GraphQL support.
Why PuppyGraph?
While many readers came here to learn about the top graph databases, PuppyGraph stands out as an option that delivers all of the benefits of a graph database without needing to deploy and maintain a graph database instance. This is done using PuppyGraph's proprietary graph query engine to integrate directly with your data sources and expose them as a graph. Let's take a closer look at the highlights and benefits.

Scalable analytics
PuppyGraph is designed to handle large data volumes with ease, making it an excellent choice for businesses that deal with big data. Its scalable analytics allow for efficient data processing, even when dealing with complex graph queries on large databases. This scalability ensures that your data processing capabilities can grow with your business, offering flexibility and future-proofing.
PuppyGraph is already used by half of the top 20 cybersecurity companies, as well as engineering-driven enterprises like AMD and Coinbase. Whether it’s multi-hop security reasoning, asset intelligence, or deep relationship queries across massive datasets, these teams trust PuppyGraph to replace slow ETL pipelines and complex graph stacks with a simpler, faster architecture.


Sub-second performance
PuppyGraph's proprietary graph query engine is optimized for speed and efficiency. It can execute complex graph queries quickly, providing real-time insights that can drive business decision-making. This high performance means you can get the information you need when needed without unnecessary delays.
Seamless integration
One of the standout features of PuppyGraph is its ability to integrate directly with your existing data sources. This seamless integration means you can start using PuppyGraph without migrating your data to a new system. This can save you significant time and effort, and it reduces the risk of data loss or corruption during migration.

No need for a separate graph database
With PuppyGraph, you can reap all the benefits of a graph database without deploying and maintaining a separate graph database instance. This is because PuppyGraph uses its graph query engine to expose your existing data as a graph. This approach can simplify your data architecture and reduce the overheads associated with maintaining multiple database instances.

In just minutes, you can start running fast graph queries on your data warehouses and data lakes. PuppyGraph offers scalability and key graph database features without added complexity.
Conclusion
Graph databases are no longer niche tools; they are now essential for businesses dealing with large, interconnected datasets. Each of the seven databases highlighted in this guide—Neo4j, AWS Neptune, TigerGraph, ArangoDB, NebulaGraph, Dgraph, and PuppyGraph—presents distinct strengths in scalability, performance, and flexibility, empowering organizations to unlock the potential of their data.
You don’t have to take our word for it. If you’re ready to start with PuppyGraph, download the forever free PuppyGraph Developer Edition or begin your free 30-day trial of the Enterprise Edition today.

Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.

Get started with PuppyGraph!


Developer Edition
- Forever free
- Single noded
- Designed for proving your ideas
- Available via Docker install
Enterprise Edition
- 30-day free trial with full features
- Everything in developer edition & enterprise features
- Designed for production
- Available via AWS AMI & Docker install