
PuppyGraph on AlloyDB: High-Performance, PostgreSQL-Compatible Graph Queries



AlloyDB is Google Cloud’s fully-managed high-performance, PostgreSQL-compatible database built for demanding transactional workloads. It delivers low-latency reads and writes with intelligent caching, scalable read pools, and advanced analytics support. It's designed to handle fast-moving data—whether it’s powering payment systems, user profiles, or IoT updates.
While relational queries are ideal for many workloads, some questions are better answered as graphs. Think user connections, network flows, or transaction paths. These use cases aren’t just about rows and joins—they’re about relationships.
PuppyGraph adds a real-time graph layer to AlloyDB. Without exporting or transforming data, teams can model their AlloyDB tables as a graph and query them using Gremlin or openCypher. It’s a fast, lightweight way to explore connected data inside your existing infrastructure.
What is AlloyDB?
AlloyDB is Google Cloud’s fully managed relational database built for high-performance operational workloads. It’s fully compatible with PostgreSQL and optimized for transactional systems that demand low-latency reads and writes—making it a strong fit for applications like e-commerce, financial transactions, and real-time user interactions.
At its core, AlloyDB uses a row-based storage model designed for rapid data access and modification. It also includes intelligent multi-tiered caching to keep frequently accessed data readily available, ensuring fast performance under heavy load.
What sets AlloyDB apart is its ability to handle both transactional and analytical workloads in the same system. It features a built-in columnar execution engine that speeds up complex queries like scans, joins, and aggregations. This makes it well-suited for hybrid scenarios—such as running real-time analytics or behavior modeling directly on live transactional data.
AlloyDB also supports scalable read pools, allowing organizations to spin up read-only replicas that can process analytical and graph queries without affecting transactional performance. This architecture helps teams build dashboards, run relationship queries, and support high-concurrency workloads while keeping the primary system responsive.
As a fully managed service, AlloyDB handles backups, patching, and high availability out of the box. It also offers independent scaling of compute and storage, making it a versatile option for teams that need operational speed, analytical flexibility, and low overhead—all in one place.
Graph Analytics with PuppyGraph on AlloyDB
AlloyDB is built for fast, reliable access to live data—whether that’s recording financial transactions, processing user actions, or powering backend systems. Its high-performance architecture, including intelligent caching, a built-in columnar engine, and scalable read pools, allows it to handle both transactional and analytical workloads in real time.
But some questions aren’t easy to answer with SQL alone—especially when they involve many layers of relationships. Questions like “Which users share devices with accounts flagged for fraud?” or “How are these transactions linked across systems over time?” require a different kind of thinking. These are graph problems.
Graph queries are designed to explore relationships. They can trace paths, identify clusters, and surface patterns that are difficult to express in SQL—especially when the logic spans multiple hops or entities. That’s where PuppyGraph comes in.
PuppyGraph lets you define a graph model directly on top of your existing AlloyDB tables. There’s no need to move or copy data to a separate graph database. You simply describe how your rows are connected—what’s a node, what’s an edge—and start querying with Gremlin or openCypher. PuppyGraph connects via JDBC using PostgreSQL wire protocol and runs alongside AlloyDB without modifying your existing setup.
Because all of this happens in real time, you can explore transactional data as it changes—whether you’re mapping customer journeys, detecting fraud patterns, or analyzing operational dependencies. PuppyGraph complements AlloyDB’s core strengths by adding a graph-native layer that reveals the relationships inside your data—without disrupting the systems that rely on it.
Architecture Overview: PuppyGraph and AlloyDB
Here’s how it works:
- Data stays in AlloyDB: PuppyGraph connects directly, so your data remains in place.
- JDBC connection: You use standard PostgreSQL wire protocol to connect securely.
- Virtual graph schema: You define how to interpret relational tables as nodes and edges.
- Query translation: Graph queries are executed in real time with optimized plans.
- Lightweight runtime: PuppyGraph runs in a container and only needs to be live during queries.
This model works well for hybrid workloads where transactional data needs fast relational insights.

Tutorial: Querying AlloyDB Tables as a Graph
This section provides a step-by-step tutorial on integrating PuppyGraph with AlloyDB. Readers will learn to establish a connection, configure a graph model over AlloyDB’s tables, and execute real-time queries to explore data relationships, leveraging its high-performance architecture. For additional guidance, readers are encouraged to consult the documentation on connecting to AlloyDB from PuppyGraph.
Prepare demo data in AlloyDB
Create a primary cluster with a primary instance in the Google Cloud Platform Console. This demonstration utilizes only a primary instance; however, readers may explore additional features such as read pools and the columnar engine at their discretion.
Connect to AlloyDB using a PostgreSQL client, such as psql. A built-in superuser, postgres, is available, with its password configured during primary cluster creation. Users may also be managed or passwords modified as needed.
```bash
psql -h <primary-instance-ip> -U <username>
```Enter the password when prompted, then execute the following SQL commands to create a schema and tables, and insert data into the default postgres database. To verify the connection, use the \c command within the PostgreSQL client.
```sql
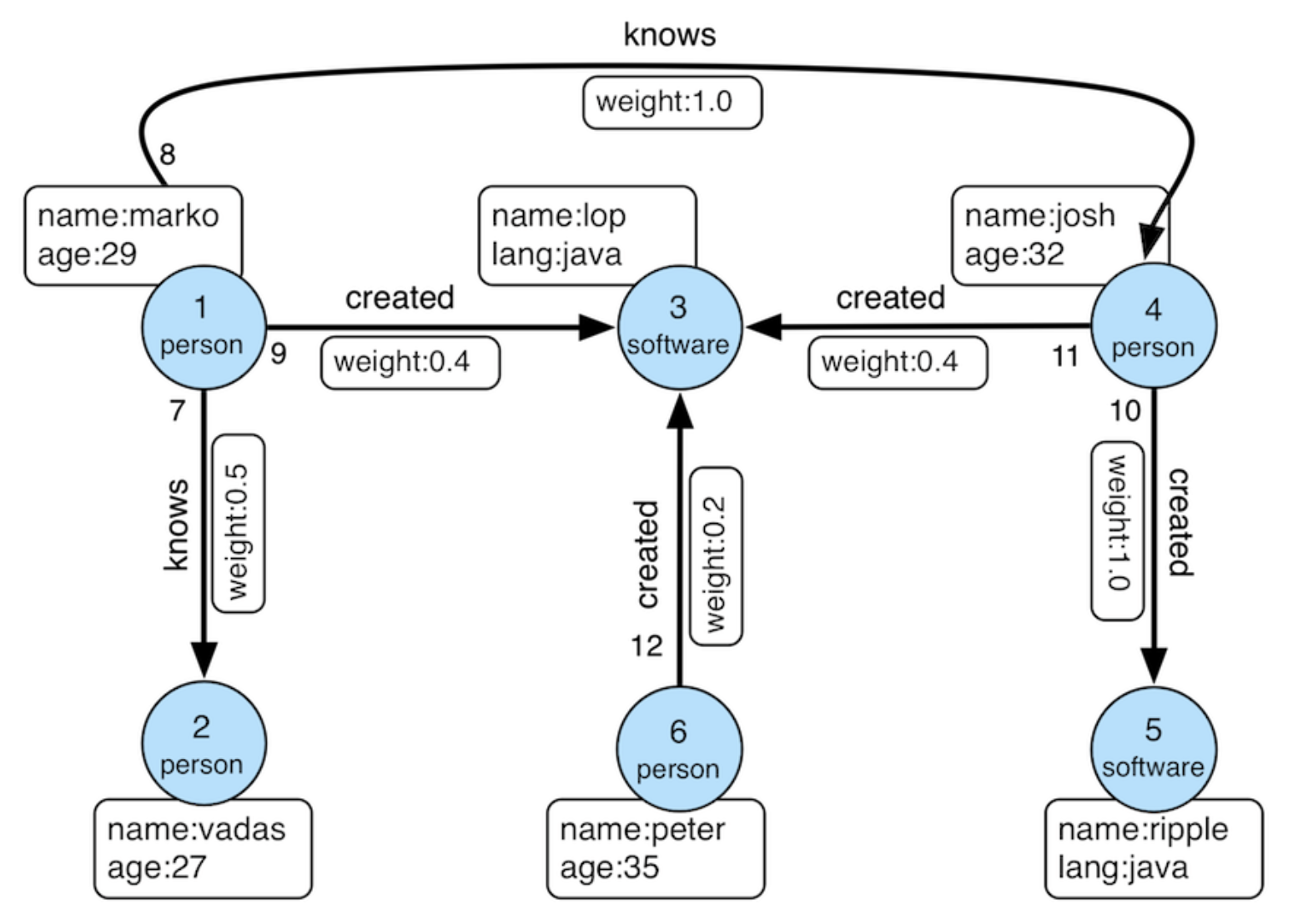
CREATE SCHEMA modern;
CREATE TABLE modern.person (id TEXT, name TEXT, age INTEGER);
INSERT INTO modern.person VALUES
('v1', 'marko', 29),
('v2', 'vadas', 27),
('v4', 'josh', 32),
('v6', 'peter', 35);
CREATE TABLE modern.software (id TEXT, name TEXT, lang TEXT);
INSERT INTO modern.software VALUES
('v3', 'lop', 'java'),
('v5', 'ripple', 'java');
CREATE TABLE modern.knows (id TEXT, from_id TEXT, to_id TEXT, weight DOUBLE PRECISION);
INSERT INTO modern.knows VALUES
('e7', 'v1', 'v2', 0.5),
('e8', 'v1', 'v4', 1.0);
CREATE TABLE modern.created (id TEXT, from_id TEXT, to_id TEXT, weight DOUBLE PRECISION);
INSERT INTO modern.created VALUES
('e9', 'v1', 'v3', 0.4),
('e10', 'v4', 'v5', 1.0),
('e11', 'v4', 'v3', 0.4),
('e12', 'v6', 'v3', 0.2);
```
Launch PuppyGraph
For AlloyDB integration, PuppyGraph may be deployed via a Docker container or the Google Cloud Marketplace. This demonstration employs the Developer Edition within a PuppyGraph Docker container. Execute the following command to initiate the container:
```bash
docker run -p 8081:8081 -p 8182:8182 -p 7687:7687 -d --name puppy --rm puppygraph/puppygraph:0.64
```You may use the latest version as shown in dockerhub.
Model the graph
Access the PuppyGraph Web UI at http://localhost:8081 with the following credentials:
- Username: `puppygraph`
- Password: `puppygraph123`
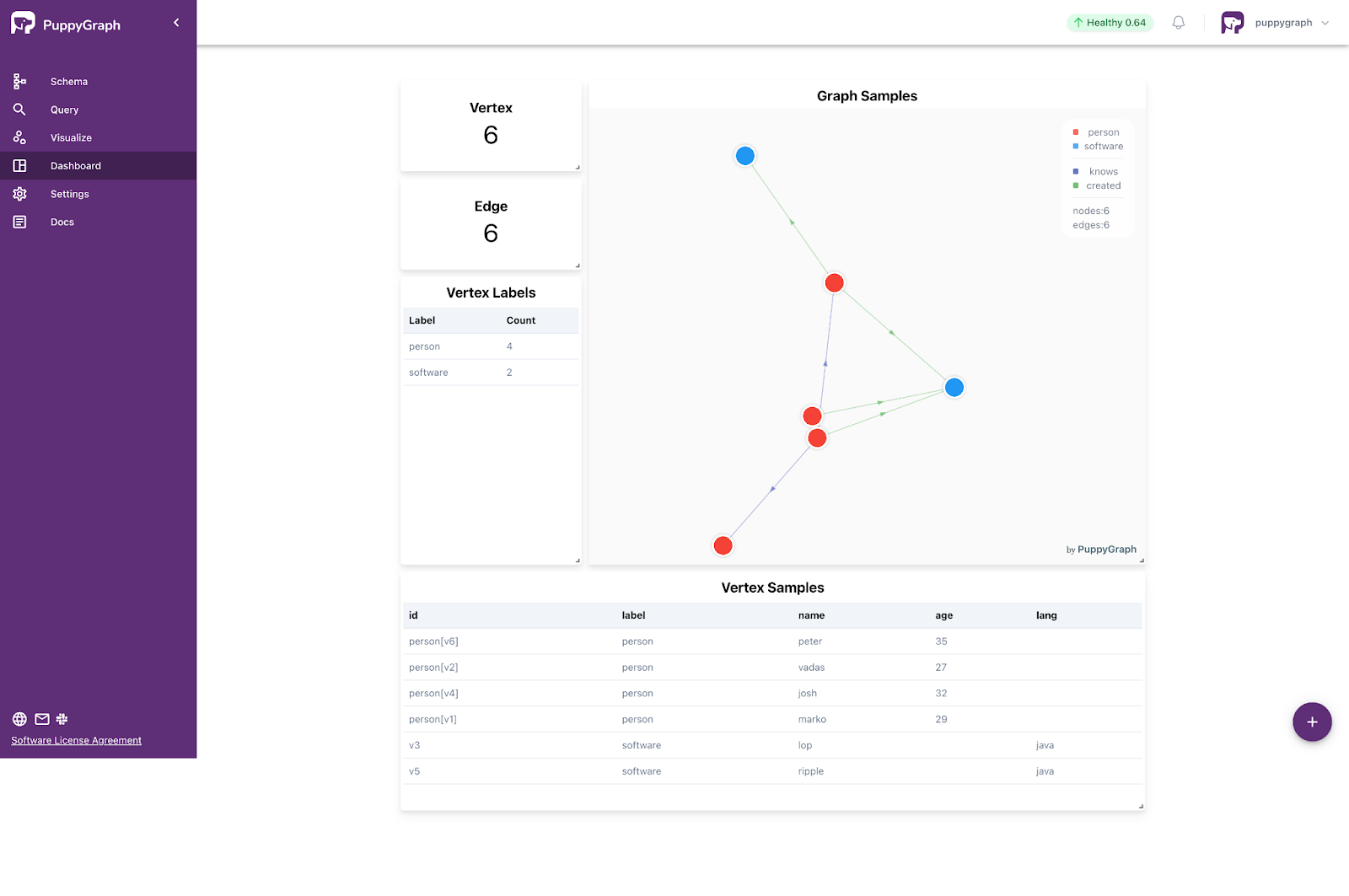
Proceed to upload the graph schema, which specifies the graph structure derived from relational data. The schema, presented below, requires replacing the jdbcUri placeholder with your actual value, using the username, password, and IP address employed during data preparation and AlloyDB connection via the PostgreSQL client. As an alternative, utilize the graph schema builder to develop the graph step-by-step, guided by the schema JSON file.
```schema.json
{
"catalogs": [
{
"name": "test",
"type": "postgresql",
"jdbc": {
"username": "<username>",
"password": "<password>",
"jdbcUri": "jdbc:postgresql://<instance-ip>:5432/postgres",
"driverClass": "org.postgresql.Driver",
"enableMetaCache": "true",
"metaCacheExpireSec": "600"
}
}
],
"graph": {
"vertices": [
{
"label": "person",
"oneToOne": {
"tableSource": {
"catalog": "test",
"schema": "modern",
"table": "person"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_id_id"
}
]
},
"attributes": [
{
"type": "STRING",
"field": "name",
"alias": "name"
},
{
"type": "INT",
"field": "age",
"alias": "age"
}
]
}
},
{
"label": "software",
"oneToOne": {
"tableSource": {
"catalog": "test",
"schema": "modern",
"table": "software"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_id_id"
}
]
},
"attributes": [
{
"type": "STRING",
"field": "name",
"alias": "name"
},
{
"type": "STRING",
"field": "lang",
"alias": "lang"
}
]
}
}
],
"edges": [
{
"label": "knows",
"fromVertex": "person",
"toVertex": "person",
"tableSource": {
"catalog": "test",
"schema": "modern",
"table": "knows"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_id_id"
}
]
},
"fromId": {
"fields": [
{
"type": "STRING",
"field": "from_id",
"alias": "puppy_from_from_id"
}
]
},
"toId": {
"fields": [
{
"type": "STRING",
"field": "to_id",
"alias": "puppy_to_to_id"
}
]
},
"attributes": [
{
"type": "DOUBLE",
"field": "weight",
"alias": "weight"
}
]
},
{
"label": "created",
"fromVertex": "person",
"toVertex": "software",
"tableSource": {
"catalog": "test",
"schema": "modern",
"table": "created"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_id_id"
}
]
},
"fromId": {
"fields": [
{
"type": "STRING",
"field": "from_id",
"alias": "puppy_from_from_id"
}
]
},
"toId": {
"fields": [
{
"type": "STRING",
"field": "to_id",
"alias": "puppy_to_to_id"
}
]
},
"attributes": [
{
"type": "DOUBLE",
"field": "weight",
"alias": "weight"
}
]
}
]
}
}
```
Query the Graph
Once the schema is uploaded, perform queries via the PuppyGraph Web UI’s Query section. Use the Graph Query interface to run Gremlin or openCypher queries and view visualized results, or select the Graph Notebook for text-only outputs from Gremlin or openCypher queries.
Here are some example queries:
1. Retrieve an vertex named 'marko'.
Gremlin:
```gremlin
g.V().has("name", "marko").valueMap()
```
openCypher:
```cypher
MATCH (v {name: 'marko'}) RETURN v
```2. Retrieve the paths from "marko" to the software created by those whom "marko" knows.
Gremlin
```gremlin
g.V().has("name", "marko")
.out("knows").out("created").path()
```OpenCypher
```cypher
MATCH p=(v {name: 'marko'})-[:knows]->()-[:created]->()
RETURN p
```
Clean up
Execute this command to stop the Docker container:
```bash
docker stop puppy
```Conclusion
AlloyDB is built for high-speed, high-scale transactional workloads. With PuppyGraph, you can go a step further—exploring the relationships inside that data using graph queries. There’s no ETL, no data movement, and no need to manage a separate graph database.
If you’re already using AlloyDB and want to explore connected data patterns, try the forever-free Developer Edition, get started via Google Cloud marketplace or book a free demo today with our graph expert team.
Jobin George is the Global Data & AI Partner Solutions & Strategy Lead at Google.
Sa Wang is a Software Engineer with exceptional mathematical ability and strong coding skills. He holds a Bachelor's degree in Computer Science and a Master's degree in Philosophy from Fudan University, where he specialized in Mathematical Logic.


